Phân tích sâu cấu trúc dữ liệu bên trong Redis (1) —— dict
2016-05-31
Chi tiết về Cấu trúc Dữ liệu Bên trong Redis
cấu trúc dữ liệu
Cấp độ đầu tiênbacarat, từ góc nhìn của người sử dụng. Ví dụ:
- string
- list
- hash
- set
- sorted set
Cấp độ này cũng là giao diện gọi được Redis cung cấp cho bên ngoài.
Cấp độ thứ haimua thẻ trực tuyến, từ góc nhìn về việc thực hiện nội bộ, thuộc về phần thực hiện ở mức thấp hơn. Ví dụ:
- dict
- sds
- ziplist
- quicklist
- skiplist
cấu trúc dữ liệu http://redis.io/topics/data-types-intro Bài viết này tập trung vào việc phân tích tầng thứ haixem ngoại hạng anh, đó là cách Redis thực hiện các cấu trúc dữ liệu bên trong và mối liên hệ giữa các cấu trúc dữ liệu ở cả hai tầng. Cụ thể, Redis làm thế nào để xây dựng các cấu trúc dữ liệu cấp cao hơn ở tầng đầu tiên bằng cách kết hợp các cấu trúc dữ liệu cơ bản từ tầng thứ hai. Qua đó, chúng ta có thể hiểu sâu hơn về cách hoạt động nội bộ của Redis và những sáng tạo độc đáo mà nó mang lại khi tối ưu hóa hiệu suất lưu trữ và xử lý dữ liệu.
Khi thảo luận về việc thực hiện nội bộ của bất kỳ hệ thống nàobacarat, điều quan trọng là trước tiên chúng ta phải xác định rõ các nguyên tắc thiết kế của nó. Điều này giúp chúng ta hiểu sâu hơn về ý định thực sự đằng sau lý do tại sao hệ thống lại được thiết kế theo cách đó. Trong phần tiếp theo của bài viết này, chúng tôi sẽ tập trung vào một số khía cạnh chính sau đây: Trước hết, việc hiểu rõ vai trò của từng thành phần trong hệ thống đóng vai trò như một nền tảng quan trọng để đánh giá toàn diện. Thứ hai, phân tích cách các yếu tố này tương tác với nhau sẽ cung cấp cho chúng ta cái nhìn toàn diện hơn về hiệu quả và mục tiêu của hệ thống. Cuối cùng, chúng ta cũng sẽ xem xét những thách thức tiềm ẩn mà hệ thống có thể gặp phải trong quá trình vận hành và cách giải quyết chúng một cách hợp lý. Hy vọng rằng bằng cách tập trung vào những điểm này, chúng ta sẽ có thể khám phá ra những điều mới mẻ và hữu ích từ hệ thống mà chúng ta đang nghiên cứu.
- Hiệu quả bộ nhớ (memory efficiency) là một yếu tố then chốt của Redisxem ngoại hạng anh, vì đây là công cụ chuyên biệt để lưu trữ dữ liệu và tiêu tốn lớn nhất của nó chính là dung lượng RAM. Việc tối ưu hóa bộ nhớ không chỉ giúp Redis hoạt động hiệu quả hơn mà còn là một trong những trọng tâm chính trong quá trình phát triển của nó. Điều này đồng nghĩa với việc Redis đã được thiết kế cẩn thận để tối ưu hóa việc nén dữ liệu, giảm thiểu mảnh vỡ bộ nhớ (memory fragmentation), cũng như cải thiện cách quản lý tài nguyên một cách thông minh. Nhờ đó, Redis có thể đạt được hiệu suất cao ngay cả khi xử lý khối lượng dữ liệu lớn trên hệ thống.
- Thời gian phản hồi nhanh (fast response time) là một trong những yếu tố quan trọng trong hệ thống. Ngược lạimua thẻ trực tuyến, khả năng xử lý dữ liệu lớn (high throughput) tập trung vào việc thực hiện nhiều yêu cầu cùng một lúc. Redis được thiết kế để phục vụ các yêu cầu trực tuyến, do đó, thời gian phản hồi nhanh luôn được ưu tiên hơn so với khả năng xử lý số lượng lớn dữ liệu. Tuy nhiên, đôi khi hai mục tiêu này có thể mâu thuẫn nhau, vì việc cải thiện một khía cạnh có thể ảnh hưởng đến khía cạnh còn lại. Trong thực tế, khi một hệ thống cần vừa đáp ứng yêu cầu nhanh chóng vừa xử lý khối lượng lớn dữ liệu, các kỹ sư phải tìm ra sự cân bằng phù hợp giữa chúng. Điều này không chỉ đòi hỏi kiến thức chuyên môn sâu mà còn cần sự sáng tạo trong việc tối ưu hóa hiệu suất tổng thể của hệ thống.
- Redis hoạt động theo mô hình đơn luồng (single-threaded)bacarat, và điểm giới hạn hiệu suất của nó không nằm ở tài nguyên CPU mà là ở việc truy cập bộ nhớ và giao tiếp mạng. Tuy nhiên, chính thiết kế đơn luồng này mang lại lợi thế lớn trong việc tối giản hóa việc triển khai cấu trúc dữ liệu và thuật toán. Ngược lại, Redis sử dụng các cơ chế như IO bất đồng bộ (asynchronous IO) và pipelining để đạt được khả năng truy cập song song nhanh chóng. Điều này đồng nghĩa với việc, với mô hình đơn luồng, mỗi yêu cầu riêng lẻ cần phải được xử lý một cách cực kỳ nhanh chóng để đảm bảo hiệu suất tổng thể. Hơn nữa, việc tối ưu hóa thời gian phản hồi cho từng yêu cầu riêng biệt trở thành yếu tố then chốt để duy trì sự ổn định và hiệu quả của hệ thống Redis.
Chi tiết về Cấu trúc Dữ liệu Bên trong Redis
Dict là một cấu trúc dữ liệu được thiết kế để duy trì mối quan hệ ánh xạ giữa key và valuebacarat, tương tự như Map hoặc dictionary trong nhiều ngôn ngữ lập trình khác. Trong Redis, tất cả các mối quan hệ key-to-value trong một database đều được duy trì thông qua một dict. Tuy nhiên, đây chỉ là một trong những ứng dụng của nó trong Redis mà thôi; thực tế, dict được sử dụng ở nhiều nơi khá Ví dụ, khi một hash trong Redis có nhiều field, nó sẽ sử dụng dict để lưu trữ. Hay nữa, Redis kết hợp dict với skiplist để cùng quản lý một tập hợp đã được sắp xếp (sorted set). Những chi tiết này chúng ta sẽ bàn bạc thêm sau, còn trong bài viết này, chúng ta sẽ tập trung vào việc tìm hiểu cách thức triển khai của dict. Dict đóng vai trò như một công cụ cốt lõi trong Redis, giúp tối ưu hóa hiệu suất lưu trữ và xử lý dữ liệu. Một số nhà phát triển còn ví von dict như "trái tim" của Redis, vì nó là cơ sở cho nhiều tính năng phức tạp hơn trong hệ thống. Điều đặc biệt thú vị là cách mà dict trong Redis được tối ưu hóa để xử lý khối lượng lớn dữ liệu đồng thời vẫn đảm bảo tốc độ và hiệu quả. Đây là một trong những yếu tố làm nên sự nổi bật của Redis trong lĩnh vực lưu trữ và xử lý dữ liệu nhanh chóng.
Dữ liệu dạng dict thực chất được thiết kế để giải quyết vấn đề tìm kiếm (Searching) trong các thuật toán. Phương pháp giải bài toán tìm kiếm thường chia thành hai nhóm chính: một nhóm dựa trên các cây cân bằng (balanced trees)xem ngoại hạng anh, và một nhóm khác dựa trên bảng băm (hash table). Những cấu trúc dữ liệu như Map hoặc dictionary mà chúng ta hay sử dụng hàng ngày chủ yếu được xây dựng dựa trên bảng băm. Khi không cần sắp xếp dữ liệu theo thứ tự và có thể duy trì xác suất xung đột băm ở mức thấp, hiệu suất tìm kiếm của bảng băm có thể đạt đến mức rất cao, gần như O(1), đồng thời cách triển khai cũng rất đơn giản. Ngoài ra, việc sử dụng bảng băm còn giúp giảm thiểu việc duyệt qua toàn bộ cấu trúc dữ liệu, điều này tiết kiệm đáng kể thời gian và tài nguyên máy tính. Tuy nhiên, nếu yêu cầu dữ liệu phải được sắp xếp theo một trật tự cụ thể, thì các cây cân bằng sẽ là lựa chọn tốt hơn, vì chúng vừa đảm bảo tính hiệu quả trong tìm kiếm vừa duy trì được thứ tự tự nhiên của dữ liệu.
Trong Redisbacarat, dict cũng là một thuật toán dựa trên bảng băm (hash table). Tương tự như các thuật toán băm truyền thống, nó sử dụng một hàm băm cụ thể để tính toán vị trí trong bảng băm dựa trên key và áp dụng phương pháp chuỗi liên kết (chaining) để giải quyết xung đột. Khi hệ số tải (load factor) vượt quá giá trị giới hạn đã đặt trước, Redis sẽ tự động mở rộng bộ nhớ và thực hiện lại việc băm (rehashing). Một đặc điểm nổi bật nhất của việc triển khai dict trong Redis chính là cách thức tái băm này. Nó sử dụng phương pháp tái băm từng bước (incremental rehashing), thay vì thực hiện toàn bộ việc tái băm cho tất cả các key cùng một lúc khi cần mở rộng bộ nhớ. Thay vào đó, các thao tác tái băm được phân tán dần dần qua các hoạt động thêm, xóa, sửa hoặc truy vấn đối với dict. Điều này giúp mỗi lần chỉ xử lý một phần nhỏ các key trong quá trình tái băm, đồng thời không làm gián đoạn các hoạt động khác của dict. Thiết kế này được thực hiện nhằm tránh việc thời gian phản hồi của một yêu cầu cụ thể tăng đột biến trong giai đoạn tái băm, phù hợp với nguyên tắc thiết kế “thời gian phản hồi nhanh” mà Redis hướng đến. Redis đã chọn cách tiếp cận này để đảm bảo rằng các hoạt động trên dict vẫn diễn ra mượt mà ngay cả khi cần mở rộng bộ nhớ. Điều này không chỉ duy trì hiệu suất ổn định mà còn giúp người dùng không cảm nhận được sự chậm trễ trong quá trình sử dụng. Phương pháp tái băm từng bước này tạo ra sự cân bằng tốt giữa hiệu quả và khả năng xử lý đồng thời, mang lại lợi ích lớn cho hệ thống Redis trong nhiều tình huống vận hành thực tế.
Dưới đây sẽ trình bày chi tiết.
Định nghĩa cấu trúc dữ liệu dict
Để thực hiện quá trình tái phân tán hash (rehashing) từng bướcmua thẻ trực tuyến, cấu trúc dữ liệu của dict bao gồm hai bảng hash. Trong suốt quá trình tái phân, dữ liệu sẽ được di chuyển từ bảng hash đầu tiên sang bảng hash thứ hai một cách có kiểm soát. Điều này giúp đảm bảo rằng việc cập nhật và truy xuất dữ liệu vẫn diễn ra ổn định mà không bị gián đoạn trong khi hệ thống đang xử lý việc điều chỉnh kích thước bảng hash.
Định nghĩa mã nguồn C của dict như sau (trích từ mã nguồn gốc dict.h của Redis):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
typedef
struct
dictEntry
{
void
*
key
;
union
{
void
*
val
;
uint64_t
u64
;
int64_t
s64
;
double
d
;
}
v
;
struct
dictEntry
*
next
;
}
dictEntry
;
typedef
struct
dictType
{
unsigned
int
(
*
hashFunction
)(
const
void
*
key
);
void
*
(
*
keyDup
)(
void
*
privdata
,
const
void
*
key
);
void
*
(
*
valDup
)(
void
*
privdata
,
const
void
*
obj
);
int
(
*
keyCompare
)(
void
*
privdata
,
const
void
*
key1
,
const
void
*
key2
);
void
(
*
keyDestructor
)(
void
*
privdata
,
void
*
key
);
void
(
*
valDestructor
)(
void
*
privdata
,
void
*
obj
);
}
dictType
;
/* This is our hash table structure. Every dictionary has two of this as we
* implement incremental rehashingmua thẻ trực tuyến, for the old to the new table. */
typedef
struct
dictht
{
dictEntry
**
table
;
unsigned
long
size
;
unsigned
long
sizemask
;
unsigned
long
used
;
}
dictht
;
typedef
struct
dict
{
dictType
*
type
;
void
*
privdata
;
dictht
ht
[
2
];
long
rehashidx
;
/* rehashing not in progress if rehashidx == -1 */
int
iterators
;
/* number of iterators currently running */
}
dict
;
Để có thể rõ ràng hơn về định nghĩa cấu trúc dữ liệu của dictmua thẻ trực tuyến, chúng ta có thể biểu diễn nó bằng một sơ đồ cấu trúc. Dưới đây là hình ảnh.
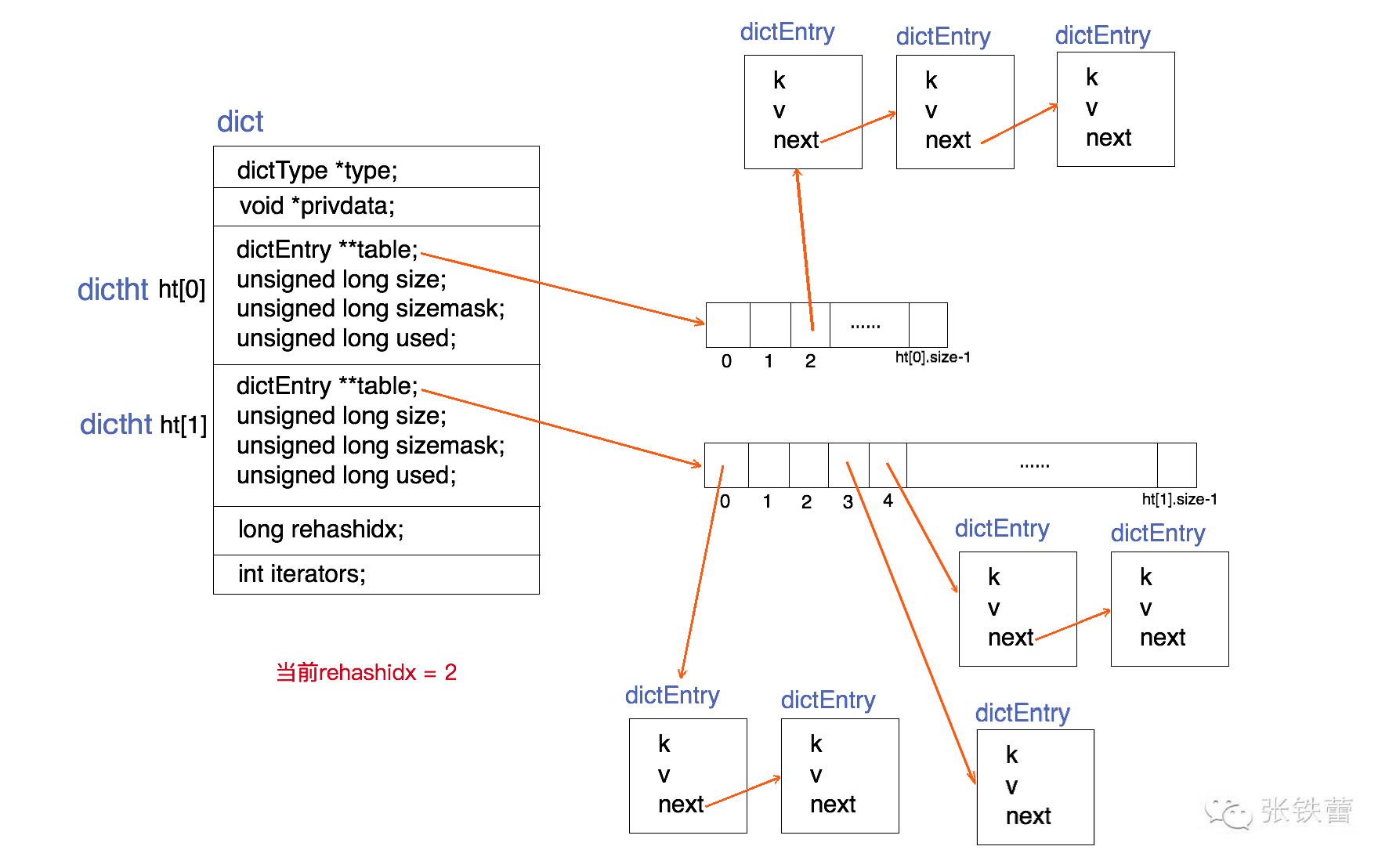
Dựa trên mã nguồn và sơ đồ cấu trúc được đề cập ở trênxem ngoại hạng anh, có thể dễ dàng nhận thấy cấu trúc của dict. Một dict bao gồm nhiều thành phần cơ bản sau đây: Đầu tiên là các cặp khóa-giá trị (key-value pairs), trong đó mỗi khóa duy nhất sẽ ánh xạ đến một giá trị cụ thể. Các cặp này đóng vai trò như những yếu tố cốt lõi giúp định hình cách hoạt động của dict. Thứ hai là khả năng linh hoạt trong việc thêm, sửa hoặc xóa các cặp khóa-giá trị, cho phép dict thay đổi theo thời gian để đáp ứng nhu cầu sử dụng khác nhau. Cuối cùng, dict còn hỗ trợ tìm kiếm nhanh chóng dựa trên khóa, nhờ vào cơ chế hashing, giúp tối ưu hóa hiệu suất khi làm việc với dữ liệu lớn. Tất cả những yếu tố này kết hợp lại tạo nên một cấu trúc dict mạnh mẽ và hữu ích trong lập trình.
- Một con trỏ hướng đến cấu trúc dictType (kiểu dữ liệu). Nó cho phép lưu trữ bất kỳ loại dữ liệu nào trong key và value của dict bằng cách sử dụng phương pháp tùy chỉnh. Nhờ đóbacarat, dict có thể linh hoạt hơn trong việc quản lý nhiều loại thông tin khác nhau mà không bị giới hạn bởi kiểu dữ liệu cố định.
- Một con trỏ dữ liệu riêng tư (privdata). Được truyền vào bởi người gọi khi tạo dict.
- Bạn có thể thấy hai bảng băm (ht[2]) trong ví dụ này. Chỉ khi quá trình tái phân tán (rehashing) diễn ramua thẻ trực tuyến, cả ht[0] và ht[1] mới cùng lúc hoạt động hiệu quả. Còn thông thường, chỉ có ht[0] được sử dụng, còn bảng ht[1] sẽ không chứa bất kỳ dữ liệu nào. Hình ảnh trên minh họa tình huống khi quá trình tái phân phối dữ liệu đang ở giữa bước thực hiện của nó.
- Tham số rehashidx hiện tại cho biết trạng thái của quá trình tái phân tán (rehash). Nếu giá trị của rehashidx là -1bacarat, điều đó có nghĩa là không có hoạt động tái phân tán nào đang diễn ra. Ngược lại, nếu nó có giá trị khác -1, điều đó cho thấy quá trình tái phân tán đang được thực hiện và giá trị này sẽ biểu thị bước hiện tại mà quá trình đã đạt được trong việc tái cấu trúc dữ liệu.
- Số lượng các iterator đang được duyệt hiện tại. Đây không phải là trọng tâm mà chúng ta đang thảo luậnbacarat, tạm thời bỏ qua.
Trong cấu trúc dictTypexem ngoại hạng anh, có chứa một số con trỏ đến hàm, cho phép người gọi của dict tùy chỉnh các thao tác liên quan đến key và value. Những thao tác này bao gồm: - Tạo và quản lý việc lưu trữ key và - So sánh hai key để xác định thứ tự hoặc tính tương đương. - Xử lý việc sao chép hoặc di chuyển giá trị từ key này sang key khác. - Xác định cách giải phóng bộ nhớ khi xóa các phần tử - Tối ưu hóa việc tìm kiếm key trong trường hợp cần thiết. Điều này giúp dictType trở nên linh hoạt hơn, phù hợp với nhiều yêu cầu khác nhau trong lập trình mà không bị giới hạn bởi một cấu trúc cố định.
- hashFunctionxem ngoại hạng anh, thuật toán hash để tính giá trị hash của key.
- keyDup và valDup là hai hàm được định nghĩa riêng để sao chép key và valuemua thẻ trực tuyến, giúp tạo ra bản sao sâu (deep copy) thay vì chỉ đơn thuần truyền tham chiếu đến đối tượng. Điều này đặc biệt hữu ích khi bạn cần đảm bảo rằng các giá trị hoặc khóa không bị ảnh hưởng bởi những thay đổi xảy ra ở nơi khác trong chương trình, từ đó tăng cường tính độc lập và độ tin cậy cho dữ liệu.
- keyComparexem ngoại hạng anh, xác định thao tác so sánh giữa hai key, được sử dụng khi tìm kiế
- Hàm keyDestructor và valDestructor sẽ xác định cách các đối tượng key và value được hủy bỏ hoặc xử lý khi chúng không còn được sử dụng. Hàm keyDestructor sẽ đảm bảo rằng mọi tài nguyên liên quan đến key đều được giải phóng một cách an toànbacarat, trong khi valDestructor sẽ thực hiện tương tự Điều này giúp duy trì tính toàn vẹn của dữ liệu và ngăn chặn rò rỉ bộ nhớ trong quá trình hoạt động của chương trình.
Con trỏ dữ liệu riêng tư (privdata) là một tham chiếu được truyền lại cho người gọi khi một số chức năng của dictType được kích hoạt. Điều này giúp duy trì trạng thái hoặc thông tin cụ thể trong quá trình thực thi các hoạt động liên quan đến cấu trúc dữ liệu này.
Cần xem xét kỹ hơn cấu trúc dictht. Nó định nghĩa cấu trúc của một bảng hashxem ngoại hạng anh, bao gồm các mục sau:
- Một mảng con trỏ dictEntry (gọi là bảng) sẽ chứa các bucket tương ứng với giá trị băm của key. Khi giá trị băm của key được tính toánmua thẻ trực tuyến, nó sẽ được ánh xạ đến một vị trí cụ thể trong bảng này. Nếu nhiều key khác nhau cùng ánh xạ đến cùng một vị trí, hiện tượng xung đột xảy ra. Khi đó, một danh sách liên kết dictEntry sẽ được tạo ra tại vị trí đó để lưu trữ tất cả các key bị xung đột.
- size: Nhận diện độ dài của mảng con trỏ Nó luôn là số mũ của 2.
- Trường sizemask được sử dụng để ánh xạ giá trị băm (hash value) đến vị trí trong bảng (table). Giá trị của nó bằng (size - 1)xem ngoại hạng anh, ví dụ như 7, 15, 31, 63, v.v., tức là những số có biểu diễn nhị phân toàn bit 1. Mỗi khóa (key) trước tiên sẽ được tính toán qua hàm băm (hashFunction) để tạo ra một giá trị băm, sau đó thực hiện phép tính (giá trị băm AND sizemask) để xác định vị trí tương ứng trong bảng. Điều này về cơ bản giống như việc tính dư (remainder) khi chia (giá trị băm % kích thước bảng). Ví dụ, nếu kích thước bảng là 8 (tức sizemask = 7), khi một giá trị băm nào đó được tính toán, chúng ta chỉ cần lấy phần dư từ phép chia cho 8 để xác định vị trí cuối cùng của khóa trong bảng. Điều này giúp tối ưu hóa hiệu suất và giảm thiểu xung đột trong việc lưu trữ dữ liệu.
- Trong trường hợp nàymua thẻ trực tuyến, "used" được dùng để ghi lại số lượng mục hiện có trong từ điển (dict). Tỷ lệ giữa giá trị của "used" và "size" sẽ cho ra hệ số tải (load factor). Khi tỷ lệ này càng cao, xác suất xảy ra xung đột giá trị băm (hash collision) cũng sẽ tăng lên. Điều này có nghĩa là khi hệ số tải lớn, việc tìm kiếm hoặc lưu trữ các phần tử trong cấu trúc dữ liệu dạng bảng băm (hash table) trở nên phức tạp hơn do nhiều khả năng các giá trị sẽ rơi vào cùng một vị trí.
Trong cấu trúc dictEntrymua thẻ trực tuyến, có chứa các thành phần k, v và con trỏ next để trỏ đến phần tử tiếp theo trong danh sách liên kết. Biến k là một con trỏ void, điều này cho phép nó có thể ánh xạ đến bất kỳ kiểu dữ liệu nào. Còn biến v là một union, khi giá trị của nó là uint64_t, int64_t hoặc double thì không cần thêm bộ nhớ bổ sung, điều này rất hữu ích trong việc giảm thiểu mảnh vụn bộ nhớ. Tất nhiên, v cũng có thể là một con trỏ void để lưu trữ bất kỳ loại dữ liệu nào. Một điểm thú vị khác là cấu trúc dictEntry được thiết kế đặc biệt để tối ưu hóa hiệu suất và sử dụng tài nguyên một cách hợp lý. Khi sử dụng union để lưu trữ các giá trị khác nhau như trên, nó giúp giảm bớt sự phức tạp trong việc quản lý bộ nhớ. Đồng thời, việc sử dụng con trỏ void cho cả k và v làm cho cấu trúc này trở nên linh hoạt hơn, phù hợp với nhiều ứng dụng khác nhau trong lập trình hệ thống.
Tạo dict (dictCreate)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
dict
*
dictCreate
(
dictType
*
type
,
void
*
privDataPtr
)
{
dict
*
d
=
zmalloc
(
sizeof
(
*
d
));
_dictInit
(
d
,
type
,
privDataPtr
);
return
d
;
}
int
_dictInit
(
dict
*
d
,
dictType
*
type
,
void
*
privDataPtr
)
{
_dictReset
(
&
d
->
ht
[
0
]);
_dictReset
(
&
d
->
ht
[
1
]);
d
->
type
=
type
;
d
->
privdata
=
privDataPtr
;
d
->
rehashidx
=
-
1
;
d
->
iterators
=
0
;
return
DICT_OK
;
}
static
void
_dictReset
(
dictht
*
ht
)
{
ht
->
table
=
NULL
;
ht
->
size
=
0
;
ht
->
sizemask
=
0
;
ht
->
used
=
0
;
}
Hàm dictCreate sẽ cấp phát bộ nhớ cho cấu trúc dữ liệu dict và gán giá trị khởi tạo cho các biến riêng lẻ. Trong đómua thẻ trực tuyến, hai bảng băm ht[0] và ht[1] ban đầu chưa được cấp phát không gian, cả hai con trỏ table đều được gán giá trị NULL. Điều này có nghĩa là việc phân bổ không gian thực sự chỉ xảy ra khi phần tử đầu tiên được thêm vào. Chính sự linh hoạt này giúp tối ưu hóa tài nguyên khi không cần sử dụng toàn bộ không gian ngay từ đầu.
Tìm kiếm dict (dictFind)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
#define dictIsRehashing(d) ((d)->rehashidx != -1)
dictEntry
*
dictFind
(
dict
*
d
,
const
void
*
key
)
{
dictEntry
*
he
;
unsigned
int
h
,
idx
,
table
;
if
(
d
->
ht
[
0
].
used
+
d
->
ht
[
1
].
used
==
0
)
return
NULL
;
/* dict is empty */
if
(
dictIsRehashing
(
d
))
_dictRehashStep
(
d
);
h
=
dictHashKey
(
d
,
key
);
for
(
table
=
0
;
table
<=
1
;
table
++
)
{
idx
=
h
&
d
->
ht
[
table
].
sizemask
;
he
=
d
->
ht
[
table
].
table
[
idx
];
while
(
he
)
{
if
(
key
==
he
->
key
||
dictCompareKeys
(
d
,
key
,
he
->
key
))
return
he
;
he
=
he
->
next
;
}
if
(
!
dictIsRehashing
(
d
))
return
NULL
;
}
return
NULL
;
}
Mã nguồn của dictFind trên đâymua thẻ trực tuyến, tùy theo dict hiện tại có đang tái phân tán hash hay không, sẽ thực hiện các bước sau:
- Nếu quá trình rehashing (điều chỉnh lại hash) đang diễn ramua thẻ trực tuyến, hãy thực hiện một bước tiến trong quá trình này (gọi hàm _dictRehashStep). Thực tế, ngoài việc tìm kiếm, các thao tác như chèn và xóa cũng có thể kích hoạt hành động này. Điều đó có nghĩa là quá trình rehashing không được tập trung vào một thao tác duy nhất mà đã được phân bổ đều qua các hoạt động tìm kiếm, chèn và xóa, giúp giảm tải và tránh gây quá tải cho hệ thống tại một thời điểm.
- Bạn có thể tính toán giá trị băm của key (gọi hàm dictHashKeybacarat, trong đó sẽ gọi đến hàm hashFunction đã được đề cập trước đó). Hàm này đóng vai trò quan trọng trong việc xác định vị trí lưu trữ dữ liệu trong bảng băm, giúp quá trình truy xuất nhanh chóng và hiệu quả.
- Ban đầubacarat, bạn hãy kiểm tra trong bảng băm đầu tiên, cụ thể là tại vị trí ht[0]. Đầu tiên, bạn cần tìm vị trí tương ứng trong mảng table bằng cách sử dụng giá trị băm (như đã đề cập trước đó, thông qua việc thực hiện phép AND logic giữa giá trị băm và sizemask). Sau khi xác định được vị trí, bạn sẽ tiếp tục tìm kiếm trong danh sách liên kết dictEntry tại vị trí đó. Khi tiến hành tìm kiếm, quá trình so sánh key sẽ được thực hiện, lúc này hàm dictCompareKeys sẽ được gọi. Trong phần thực thi của hàm dictCompareKeys, nó sẽ gọi đến hàm keyCompare mà chúng ta đã đề cập trước đó. Nếu tìm thấy key phù hợp, kết quả sẽ được trả về ngay lập tức. Nếu không, bạn sẽ phải chuyển sang bước tiếp theo.
- Bạn có thể xác định xem hiện tại có đang ở giai đoạn tái phân tán (rehashing) hay không. Nếu khôngxem ngoại hạng anh, kết quả tìm kiếm trên bảng `ht[0]` sẽ là kết quả cuối cùng (nếu không tìm thấy, trả về NULL). Ngược lại, nếu đang ở giai đoạn tái phân tán, hãy tiến hành tìm kiếm trên bảng `ht[1]`, với quy trình giống như bước trước đó. Trong trường hợp này, việc kiểm tra trạng thái của hệ thống lưu trữ dữ liệu đóng vai trò quan trọng để đảm bảo hiệu suất và tính chính xác khi xử lý các yêu cầu truy vấn. Nếu quá trình tái phân phối key giữa các bảng hash đang diễn ra, bạn cần điều chỉnh logic để tiếp tục tìm kiếm trong bảng tiếp theo một cách hợp lý.
Tiếp theobacarat, chúng ta cần xem xét cách thực hiện của _dictRehashStep để tái phân tán hash từng bước.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
static
void
_dictRehashStep
(
dict
*
d
)
{
if
(
d
->
iterators
==
0
)
dictRehash
(
d
,
1
);
}
int
dictRehash
(
dict
*
d
,
int
n
)
{
int
empty_visits
=
n
*
10
;
/* Max number of empty buckets to visit. */
if
(
!
dictIsRehashing
(
d
))
return
0
;
while
(
n
--
&&
d
->
ht
[
0
].
used
!=
0
)
{
dictEntry
*
de
,
*
nextde
;
/* Note that rehashidx can't overflow as we are sure there are more
* elements because ht[0].used != 0 */
assert
(
d
->
ht
[
0
].
size
>
(
unsigned
long
)
d
->
rehashidx
);
while
(
d
->
ht
[
0
].
table
[
d
->
rehashidx
]
==
NULL
)
{
d
->
rehashidx
++
;
if
(
--
empty_visits
==
0
)
return
1
;
}
de
=
d
->
ht
[
0
].
table
[
d
->
rehashidx
];
/* Move all the keys in this bucket from the old to the new hash HT */
while
(
de
)
{
unsigned
int
h
;
nextde
=
de
->
next
;
/* Get the index in the new hash table */
h
=
dictHashKey
(
d
,
de
->
key
)
&
d
->
ht
[
1
].
sizemask
;
de
->
next
=
d
->
ht
[
1
].
table
[
h
];
d
->
ht
[
1
].
table
[
h
]
=
de
;
d
->
ht
[
0
].
used
--
;
d
->
ht
[
1
].
used
++
;
de
=
nextde
;
}
d
->
ht
[
0
].
table
[
d
->
rehashidx
]
=
NULL
;
d
->
rehashidx
++
;
}
/* Check if we already rehashed the whole table... */
if
(
d
->
ht
[
0
].
used
==
0
)
{
zfree
(
d
->
ht
[
0
].
table
);
d
->
ht
[
0
]
=
d
->
ht
[
1
];
_dictReset
(
&
d
->
ht
[
1
]);
d
->
rehashidx
=
-
1
;
return
0
;
}
/* More to rehash... */
return
1
;
}
Mỗi lần thực hiện dictRehashxem ngoại hạng anh, ít nhất n bước của quá trình tái phân tán sẽ được tiến hành (trừ khi toàn bộ quá trình tái phân tán kết thúc trong vòng chưa đến n bước). Ở mỗi bước, từng dictEntry trong một bucket cụ thể của ht[0] (một danh sách liên kết dictEntry) sẽ được di chuyển sang ht[1], và vị trí mới của chúng trên ht[1] sẽ được tính toán lại dựa trên sizemask của ht[1]. Biến rehashidx lưu trữ vị trí hiện tại của bucket trong ht[0] mà vẫn chưa được di chuyển (còn đang chờ xử lý).
Khi hàm dictRehash được gọimua thẻ trực tuyến, nếu bucket mà rehashidx đang chỉ đến hoàn toàn trống và không có bất kỳ dictEntry nào, điều đó có nghĩa là không có dữ liệu nào cần được di chuyển trong trường hợp này. Tại thời điểm này, nó sẽ cố gắng duyệt qua các phần tử của mảng ht[0].table để tìm kiếm một bucket tiếp theo chứa dữ liệu. Nếu không thể tìm thấy bucket nào chứa dữ liệu trong quá trình này, nó sẽ dừng lại sau khi thực hiện tối đa n * 10 bước. Khi đó, quá trình tái phân tán (rehashing) tạm thời sẽ kết thúc. Quá trình này đảm bảo rằng hệ thống không bị kẹt trong vòng lặp vô tận khi không còn dữ liệu khả dụng để xử lý, đồng thời giúp duy trì hiệu suất ổn định cho hoạt động quản lý bảng băm.
Cuối cùngbacarat, nếu tất cả dữ liệu trên ht[0] đã được di chuyển sang ht[1] (tức là d->ht[0].used == 0), quá trình tái phân tán hash sẽ kết thúc. Lúc này, ht[0] sẽ chứa nội dung của ht[1], trong khi ht[1] sẽ được đặt lại trạng thái trống, sẵn sàng cho các hoạt động tiếp theo. Quá trình này đảm bảo rằng cấu trúc dữ liệu luôn được sắp xếp lại một cách hiệu quả và tối ưu hóa cho các thao tác tiếp theo.
Dựa trên phân tích về quá trình tái phân tán hash (rehashing) đã nêu trênbacarat, chúng ta có thể dễ dàng nhận ra rằng hình ảnh cấu trúc dict được trình bày trong phần đầu bài viết chính là trường hợp khi rehashidx = 2. Hai bucket đầu tiên (ht[0].table[0] và ht[0].table[1]) đã được di chuyển hoàn toàn sang ht[1]. Quá trình này cho thấy sự chuyển đổi dữ liệu từ bảng băm ban đầu sang bảng băm mới đang diễn ra một cách trơn tru.
Chèn dict (dictAdd và dictReplace)
dictAdd chèn cặp mới key và valuemua thẻ trực tuyến, nếu key đã tồn tại, thì việc chèn sẽ thất bại.
Hàm dictReplace cũng thêm vào một cặp key và valuebacarat, nhưng khi key đã tồn tại, nó sẽ cập nhật giá trị value tương ứng. Thay vì chỉ thêm mới, hàm này giúp bạn dễ dàng chỉnh sửa nội dung trong từ điển mà không cần phải xóa hay tạo lại toàn bộ. Điều này đặc biệt hữu ích khi bạn muốn duy trì tính nhất quán của dữ liệu mà không làm mất đi các thông tin quan trọng đã có trước đó.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
int
dictAdd
(
dict
*
d
,
void
*
key
,
void
*
val
)
{
dictEntry
*
entry
=
dictAddRaw
(
d
,
key
);
if
(
!
entry
)
return
DICT_ERR
;
dictSetVal
(
d
,
entry
,
val
);
return
DICT_OK
;
}
dictEntry
*
dictAddRaw
(
dict
*
d
,
void
*
key
)
{
int
index
;
dictEntry
*
entry
;
dictht
*
ht
;
if
(
dictIsRehashing
(
d
))
_dictRehashStep
(
d
);
/* Get the index of the new elementmua thẻ trực tuyến, or -1 if
* the element already exists. */
if
((
index
=
_dictKeyIndex
(
d
,
key
))
==
-
1
)
return
NULL
;
/* Allocate the memory and store the new entry.
* Insert the element in topbacarat, with the assumption that in a database
* system it is more likely that recently added entries are accessed
* more frequently. */
ht
=
dictIsRehashing
(
d
)
?
&
d
->
ht
[
1
]
:
&
d
->
ht
[
0
];
entry
=
zmalloc
(
sizeof
(
*
entry
));
entry
->
next
=
ht
->
table
[
index
];
ht
->
table
[
index
]
=
entry
;
ht
->
used
++
;
/* Set the hash entry fields. */
dictSetKey
(
d
,
entry
,
key
);
return
entry
;
}
static
int
_dictKeyIndex
(
dict
*
d
,
const
void
*
key
)
{
unsigned
int
h
,
idx
,
table
;
dictEntry
*
he
;
/* Expand the hash table if needed */
if
(
_dictExpandIfNeeded
(
d
)
==
DICT_ERR
)
return
-
1
;
/* Compute the key hash value */
h
=
dictHashKey
(
d
,
key
);
for
(
table
=
0
;
table
<=
1
;
table
++
)
{
idx
=
h
&
d
->
ht
[
table
].
sizemask
;
/* Search if this slot does not already contain the given key */
he
=
d
->
ht
[
table
].
table
[
idx
];
while
(
he
)
{
if
(
key
==
he
->
key
||
dictCompareKeys
(
d
,
key
,
he
->
key
))
return
-
1
;
he
=
he
->
next
;
}
if
(
!
dictIsRehashing
(
d
))
break
;
}
return
idx
;
}
Đây là mã nguồn quan trọng của dictAdd. Chúng ta cần lưu ý những điểm sau:
- Nó cũng sẽ kích hoạt một bước tái phân tán hash (_dictRehashStep).
- Nếu đang trong quá trình tái phân tán hashxem ngoại hạng anh, nó sẽ chèn dữ liệu vào ht[1]; nếu không, chèn vào ht[0].
- Khi chèn dữ liệu vào bucket tương ứngxem ngoại hạng anh, dữ liệu luôn được thêm vào đầu củ Lý do là vì xác suất dữ liệu mới sẽ được truy cập tiếp theo thường cao hơn, nhờ đó khi tìm kiếm lại dữ liệu này sau này, số lần so sánh cần thiết sẽ giảm đi đáng kể. Điều này giúp tối ưu hóa hiệu suất hoạt động của hệ thống, đặc biệt trong các trường hợp xử lý dữ liệu lớn và yêu cầu tốc độ truy xuất nhanh chóng.
- _key chỉ số được sử dụng để tìm kiếm vị trí chèn trong từ điển. Nếu không ở trong quá trình tái phân tánmua thẻ trực tuyến, nó chỉ kiểm tra ht[0]; ngược lại, nó sẽ kiểm tra cả ht[0] và ht[1].
- Biến `_dictKeyIndex` có thể kích hoạt việc mở rộng bộ nhớ của đối tượng `dict` (thông qua hàm `_dictExpandIfNeeded`mua thẻ trực tuyến, hàm này sẽ tăng gấp đôi kích thước bảng băm. Để biết thêm chi tiết, xin vui lòng tham khảo mã nguồn trong tệp `dict.c`).
dictReplace được xây dựng dựa trên dictAddbacarat, như sau:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
int
dictReplace
(
dict
*
d
,
void
*
key
,
void
*
val
)
{
dictEntry
*
entry
,
auxentry
;
/* Try to add the element. If the key
* does not exists dictAdd will suceed. */
if
(
dictAdd
(
d
,
key
,
val
)
==
DICT_OK
)
return
1
;
/* It already existsbacarat, get the entry */
entry
=
dictFind
(
d
,
key
);
/* Set the new value and free the old one. Note that it is important
* to do that in this orderbacarat, as the value may just be exactly the same
* as the previous one. In this context, think to reference counting,
* you want to increment (set), and then decrement (free), and not the
* reverse. */
auxentry
=
*
entry
;
dictSetVal
(
d
,
entry
,
val
);
dictFreeVal
(
d
,
&
auxentry
);
return
0
;
}
Trong trường hợp key đã tồn tạixem ngoại hạng anh, dictReplace sẽ gọi đồng thời cả dictAdd và dictFind, điều này về cơ bản giống như thực hiện hai lần quá trình tìm kiếm. Tại đây, đoạn mã của Redis chưa được tối ưu hóa một cách hiệu quả. Việc thực hiện đồng thời dictAdd và dictFind có thể dẫn đến sự lãng phí tài nguyên, đặc biệt là khi xử lý các tập dữ liệu lớn. Thay vì chạy song song hai hàm này, có thể thiết kế một giải pháp duy nhất vừa thêm vừa kiểm tra tính tồn tại của key trong một bước duy nhất. Điều này không chỉ giúp giảm thiểu thời gian thực thi mà còn cải thiện hiệu suất tổng thể của Redis. Tuy nhiên, cần cân nhắc rằng việc tối ưu hóa sâu hơn cũng có thể làm tăng độ phức tạp của mã nguồn, do đó cần có sự đánh đổi giữa hiệu suất và khả năng bảo trì. Nhưng với yêu cầu ngày càng cao của người dùng đối với hiệu suất hệ thống, việc cải tiến mã nguồn để tối ưu hóa các hoạt động như dictReplace là điều cần thiết.
Xóa dict (dictDelete)
Mã nguồn của dictDelete ở đây được bỏ quaxem ngoại hạng anh, vui lòng tham khảo dict.c. Cần chú ý thêm:
- dictDelete cũng sẽ kích hoạt một bước tái phân tán hash (_dictRehashStep).
- Nếu không đang ở giữa quá trình rehashingmua thẻ trực tuyến, nó sẽ chỉ tìm kiếm key cần xóa trong bảng ht[0]. Tuy nhiên, nếu đang trong quá trình rehashing, nó sẽ phải kiểm tra cả hai bảng ht[0] và ht[1] để đảm bảo tìm được key một cách chính xác.
- Sau khi xóa thành côngxem ngoại hạng anh, các hàm huỷ của khóa (keyDestructor) và giá trị (valDestructor) sẽ được gọi để giải phóng tài nguyên. Điều này đảm bảo rằng mọi thứ được dọn dẹp một cách gọn gàng trước khi đối tượng bị xóa khỏi bộ nhớ.
Việc triển khai kiểu dữ liệu dict tương đối dễ hiểubacarat, và nội dung bài viết hôm nay xin được dừng tại đây. Trong bài viết tiếp theo, chúng ta sẽ cùng tìm hiểu về cách thức thực hiện chuỗi động trong Redis – SDS (Simple Dynamic String), hãy chờ đón những chia sẻ thú vị sắp tới nhé!
Bài viết gốcmua thẻ trực tuyến, xin vui lòng trích dẫn nguồn và bao gồm mã QR bên dưới! Nếu không, từ chối tái bản!
Liên kết bài viết: /jzpzxx88.html
Hãy theo dõi tài khoản Weibo cá nhân của tôi: Tìm kiếm tên tôi "Trương Thiết Lệ" trên Weibo.

Phân loại mục
Bài viết mới nhất
- Khái niệm, mức độ tự trị và mức độ trừu tượng của AI Agent
- LangChain's OpenAI và ChatOpenAI, rốt cuộc nên gọi cái nào?
- Phần tiếp theo của DSPy: Tìm hiểu thêm về o1, Lượng tính tại thời gian suy luận (Inference-time Compute) và Khả năng lý luận (Reasoning) Trong phần này, chúng ta sẽ đi sâu vào khám phá thế giới của o1, một ngôn ngữ lập trình hướng đối tượng được thiết kế đặc biệt để tối ưu hóa hiệu suất và giảm thiểu tài nguyên sử dụng. o1 không chỉ là một công cụ mạnh mẽ mà còn mở ra cánh cửa cho các khả năng mới trong việc xây dựng ứng dụng thông minh. Tiếp theo, chúng ta sẽ thảo luận về lượng tính tại thời gian suy luận (Inference-time Compute), một khái niệm quan trọng trong lĩnh vực trí tuệ nhân tạo và học máy. Điều này liên quan đến việc xác định và tối ưu hóa lượng tài nguyên cần thiết khi mô hình AI thực hiện các hoạt động suy luận hoặc đưa ra quyết định dựa trên dữ liệu đầu vào. Cuối cùng, chúng ta sẽ xem xét vai trò của lý luận (Reasoning) trong hệ thống AI. Lý luận là khả năng của một hệ thống AI để phân tích thông tin, rút ra kết luận và đưa ra quyết định dựa trên cơ sở logic. Điều này không chỉ giúp cải thiện độ chính xác mà còn nâng cao khả năng thích nghi của AI trong môi trường phức tạp. Tất cả những yếu tố này cùng nhau đóng góp vào sự phát triển của các hệ thống AI tiên tiến hơn, linh hoạt hơn và hiệu quả hơn trong việc giải quyết các vấn đề thực tế.
- Nói chuyện sơ lược về DSPy và kỹ thuật tự động hóa nhắc nhở (phần giữa)
- Nói chuyện sơ lược về DSPy và kỹ thuật tự động hóa nhắc nhở (phần đầu)
- Giải thích khoa học: Phân tích nguyên lý xác suất đằng sau LLM
- Bắt đầu từ Vương Tiểu Bảo: Ranh giới đạo đức và quan điểm thiện ác của người bình thường
- Xem xét lại thông tin từ GraphRAG
- Những thay đổi và bất biến trong sự thay đổi công nghệ: Làm thế nào để tạo ra token nhanh hơn?
- Thể trí thông minh doanh nghiệp, số hóa và phân công ngành nghề