Giải thích khoa học: Phân tích nguyên lý xác suất đằng sau LLM
2024-11-01
Khi tôi lái xe đưa cả gia đình đi du lịch dài ngàymua thẻ trực tuyến, để giết thời gian, chúng tôi đôi khi sẽ chơi trò "đặt từ theo vần", giống như thế này:
Biển rộng trời cao
Trước nay chưa từng có789 Club, sau này không bao giờ lặp lại
Chiến lược tấn công sau khi đối thủ ra đòn
Người đông như rừng
…
Quy tắc của trò chơi làcá cược bóng đá, mỗi người lần lượt nói một thành ngữ.
người đông người vắng
Xác suất điều kiện và dự đoán token tiếp theo
trò chơi dây xích
Trong trò chơi nối từ thành ngữ789 Club, chúng ta dựa trên từ thành ngữ trước để "dự đoán" từ thành ngữ tiếp theo. Còn khi nói hoặc viết, chúng ta không ngừng "dự đoán" chữ tiếp theo hoặc từ tiếp theo. Mặc dù luật ngữ cảnh mạnh mẽ như trong trò chơi nối từ thành ngữ đã không còn tồn tại nữa, nhưng chúng ta vẫn luôn cần phải tìm kiếm trong một không gian ngôn ngữ rộng lớn hơn để chọn ra những câu từ phù hợp, làm cho câu nói hoặc đoạn văn trở nên tự nhiên và tuân theo các quy tắc ngữ pháp cơ bản cũng như thông thường nhất. Điều này đòi hỏi khả năng hiểu biết sâu sắc về ngôn ngữ và sự linh hoạt trong việc kết nối ý tưởng.
Rất có thể nhiều người đã từng trải qua cảm giác như vậy: khi tham gia cuộc gọi từ xa789 Club, dù tín hiệu không ổn định và gián đoạn liên tục, bạn vẫn có thể hiểu được phần nào ý nghĩa mà người kia muốn truyền đạt. Lý do là vì bộ não của bạn, dựa trên kiến thức ngôn ngữ và những hiểu biết thông thường mà bạn đã tích lũy được, sẽ nhanh chóng "dự đoán" và điền vào các khoảng trống trong những từ hoặc câu mà tín hiệu làm mất đi. Không chỉ dừng lại ở đó, khả năng này còn giúp chúng ta dễ dàng thích nghi với nhiều tình huống giao tiếp khác nhau, từ việc nghe tiếng nói bị nhiễu cho đến việc giải mã các đoạn hội thoại phức tạp hơn. Điều này cho thấy trí óc con người thật sự là một cỗ máy đáng kinh ngạc trong việc xử lý thông tin và đưa ra phán đoán kịp thời!
Trong xử lý ngôn ngữ tự nhiên (NLP)mua thẻ trực tuyến, chúng ta thường sử dụng một Xác suất điều kiện Để mô tả phân phối xác suất của quá trình dự đoán này.
Giả sử chúng ta đã biết đoạn văn bản phía trước
n-1
ký tự:
w
1
w
2
…w
n-1
mua thẻ trực tuyến, thì xác suất ký tự thứ
n
xuất hiện sẽ là:
w
n
cá cược bóng đá, mỗi biến đại diện cho một token.
P(w n |w 1 w 2 …w n-1 )
Hiện tạicá cược bóng đá, các mô hình ngôn ngữ lớn (LLM) đã đạt được khả năng hiểu và dự đoán điều này thông qua việc đào tạo trên một kho dữ liệu văn bản khổng lồ. Chúng học cách tính xác suất có điều kiện của từng từ hoặc cụm từ xuất hiện theo thứ tự nhất định (cách hoạt động cụ thể của quá trình này sẽ được thảo luận chi tiết trong các chương sau). Tuy nhiên, khi thực hiện dự đoán, LLM không trực tiếp làm việc với các ký tự hoặc từ đơn lẻ mà thay vào đó sử dụng các "token". Token là những phần nhỏ hơn, thường là các từ hoặc nhóm từ đã được tiền xử lý và chuẩn hóa, giúp mô hình dễ dàng hơn trong việc phân tích và dự đoán chuỗi tiếp theo. Điều này được gọi là...
predict next token
。
Trong bài viết nàycá cược bóng đá, tôi không có ý định đi sâu vào những chi tiết như sự khác biệt giữa token và từ. Người đọc có thể tạm coi một token như một chữ cái hoặc một từ đơn (điều này sẽ không ảnh hưởng đến việc nắm bắt ý chính). Tuy nhiên, ở các phần sau, chúng ta sẽ chuyển sang sử dụng khái niệm token để diễn giải. Nói cách khác, từ đây về sau, chúng ta sẽ... w 1 Công thức trước đó w n mua thẻ trực tuyến, biểu thị rằng, trong trường hợp đã biết tiền token đầu tiên
tokenmua thẻ trực tuyến, xác suất có điều kiện để dự đoán token thứ
P(w
n
|w
1
w
2
…w
n-1
)
được tính toán.
n-1
Phân phối xác suất liên hợp và mô hình sinh
n
Giả sử một LLM cụ thể đã học cách dự đoán xác suất có điều kiện trước đó789 Club, vậy,
Chúng ta biết rằng trong học máycá cược bóng đá, có ba phương pháp giải quyết vấn đề phân loại [1], từ phức tạp nhất đến đơn giản nhất:
: Mô hình sinh. Dự đoán trực tiếp toàn bộ phân phối xác suất liên hợp
w
n
Bạn có thể thực hiện việc này trên toàn bộ từ điển. Điều đó có nghĩa là789 Club, với bất kỳ token nào có khả năng xảy ra trong từ điển, mô hình ngôn ngữ lớn (LLM) đều có thể dự đoán được vị trí của nó trong chuỗi một cách chính xác. Hãy tưởng tượng rằng từ điển như một kho tàng khổng lồ chứa đựng tất cả các từ và cụm từ có thể xuất hiện, và LLM giống như một nhà thông thái luôn sẵn sàng chỉ ra thứ tự mà chúng sẽ xuất hiện trong bất kỳ câu chuyện nào. Điều này mở ra cánh cửa cho khả năng hiểu và tạo ra ngôn ngữ theo cách gần gũi nhất với con người.
n
Vị trí xuất hiện của ký tự trong một chuỗi có thể được tính toán xác suất. Trong lĩnh vực học máycá cược bóng đá, đây thực chất là một bài toán phân loại, nhưng thách thức ở chỗ số lượng các lớp phân loại mà chúng ta cần đối mặt là vô cùng lớn. Hãy lấy ví dụ về tiếng Hán: tổng số chữ Hán khoảng chừng vài trăm nghìn (tương đương với kích thước của từ điển token cũng nằm ở mức đó). Ngoài ra, khi nói đến việc xây dựng mô hình dựa trên ngôn ngữ, việc xử lý và tối ưu hóa các ký tự trong một từ điển khổng lồ này đòi hỏi sự khéo léo và chiến lược rõ ràng. Mỗi chữ không chỉ đơn thuần là một ký hiệu, mà còn mang theo ý nghĩa văn hóa và ngữ nghĩa sâu sắc, khiến vấn đề trở nên phức tạp hơn bao giờ hết.
: Mô hình phân biệt. Chỉ dự đoán phân phối xác suất có điều kiện hậu nghiệm
-
Generative Model: Hàm phân biệt. Đưa trực tiếp đầu vào P(x,C k ) 。 -
Discriminative Modelánh xạ sang lớp P(C k |x) 。 -
Discriminant Functionmà không liên quan đến phân phối xác suất. x Áp dụng vào LLM789 Club, chúng ta phát hiện rằng: C k Phân phối xác suất liên hợpmua thẻ trực tuyến, tương đương với việc tính toán
Phân phối xác suất có điều kiệncá cược bóng đá, tương đương với việc tính toán
- Trong phần nhỏ trước đó789 Club, chúng tôi đã đưa ra công thức xác suất có điều kiện, LLM có thể sử dụng nó để P(w 1 w 2 …w n-1 w n ) 。
- . Vậycá cược bóng đá, điều này có nghĩa là LLM thuộc về mô hình phân biệt? P(w n |w 1 w 2 …w n-1 ) 。
cá cược bóng đá, từ đó rõ ràng nó thuộc về mô hình sinh.
predict next token
Điều này là thế nào? Đối với việc mô hình hóa chuỗi789 Club, có những đặc điểm riêng. Khi chúng ta nói rằng mô hình có thể dự đoán xác suất có điều kiện
Chờ đãmua thẻ trực tuyến, có vẻ như có điều gì đó không ổn! Những mô hình ngôn ngữ lớn (LLM) phổ biến nhất hầu hết đều dựa trên kiến trúc GPT. Mọi người đều biết rằng GPT viết tắt của **Generative Pre-trained Transformer**. Đây là một mô hình được huấn luyện trước và có khả năng tạo ra văn bản một cách tự nhiên bằng cách sử dụng các thuật toán chuyển tiếp (transformer). Điều đặc biệt ở đây là nó không chỉ học từ dữ liệu được cung cấp mà còn có thể suy luận và tạo ra nội dung mới dựa trên ngữ cảnh mà nó nhận được. Chính vì vậy, GPT đã trở thành nền tảng cho rất nhiều ứng dụng hiện đại trong lĩnh vực trí tuệ nhân tạo ngày nay.
Generative Pre-trained Transformer
mua thẻ trực tuyến, ý của chúng ta là dự đoán này áp dụng cho bất kỳ
Generative
nào! Nói cách khác789 Club, xác suất có điều kiện sau đây, LLM đều có thể dự đoán được:
Chúng ta nhận thấy789 Club, theo quy luật xích của lý thuyết xác suất, khi nhân tất cả các xác suất có điều kiện trên lại với nhau, rồi nhân thêm một P(w n |w 1 w 2 …w n-1 ) ở phía trước789 Club, sẽ thu được: n 789 Club, nhưng thực tế LLM luôn nhập một chuỗi tiền tố có độ dài lớn hơn 0 khi tạo ra, do đó yếu tố thừa này
- P(w 2 |w 1 )
- P(w 3 |w 1 w 2 )
- P(w 4 |w 1 w 2 w 3 )
- …
- P(w n |w 1 w 2 …w n-1 )
không ảnh hưởng đến tổng thể. P(w 1 ) Do đómua thẻ trực tuyến, chúng ta có thể nói,
P(w 1 ) P(w 2 |w 1 ) P(w 3 |w 1 w 2 ) … P(w n |w 1 w 2 …w n-1 ) = P(w 1 w 2 …w n-1 w n )
Rõ ràngcá cược bóng đá, LLM có khả năng dự đoán phân phối xác suất liên hợp của một chuỗi (chỉ cần thực hiện qua nhiều bước, mỗi bước dự đoán một token). Về mặt kỹ thuật, biểu thức ở phía bên trái còn bao gồm thêm một yếu tố khác. Cụ thể hơn, thay vì chỉ đơn thuần tính toán giá trị cuối cùng, mô hình này thực sự áp dụng chuỗi các phép biến đổi để làm nổi bật ngữ cảnh trước đó và từ đó xây dựng dự đoán chính xác nhất cho từng token tiếp theo. Điều này không chỉ giúp tăng cường hiệu quả mà còn cải thiện độ chính xác trong việc giải thích ngữ nghĩa tổng thể của đoạn văn bản. Như vậy, mặc dù quy trình có vẻ phức tạp, nhưng LLM thực sự là một công cụ mạnh mẽ trong việc tạo ra nội dung có ý nghĩa và mạch lạc. P(w 1 ) Theo một số lý thuyết cơ bản của học máy789 Club, chúng ta biết rằng ưu và nhược điểm chính của mô hình sinh là như sau: P(w 1 ) Nhược điểm: Yêu cầu sức mạnh tính toán và kích thước dữ liệu huấn luyện cực lớn.
Những tình huống này phù hợp với thực tế của LLM. Mô hình LLM thực sự là một mô hình tạo sinh. Ở phần nhỏ trước đó về xác suất điều kiện và phần này về phân phối xác suất liên hợp789 Club, cả hai đều có thể diễn giải một cách tương đương khả năng của LLM. Tuy nhiên, cần lưu ý rằng khía cạnh tạo sinh trong LLM không chỉ giới hạn ở việc tính toán các giá trị xác suất mà còn bao hàm khả năng tạo ra dữ liệu mới một cách sáng tạo và tự nhiên, giúp mô hình này trở thành một công cụ mạnh mẽ trong nhiều ứng dụng khác nhau.
Tách rời và liên tục
- Ưu điểm: Do mô hình tạo sinh đã học được phân phối xác suất liên hợpmua thẻ trực tuyến, nó có thể dễ dàng tạo ra các mẫu dữ liệu mới một cách tự nhiên. Chính khả năng này giúp nó trở nên phù hợp cho việc giải quyết các nhiệm vụ sáng tạo như tạo hình ảnh, viết văn bản hoặc thậm chí phát triển âm nhạc, mang lại tiềm năng vô tận trong việc khai thác các ứng dụng nghệ thuật và kỹ thuật số. Tôi đã thêm một số chi tiết để làm phong phú thêm nội dung mà vẫn giữ nguyên ý nghĩa của đoạn gốc. Tất cả đều bằng tiếng Việt.
- Trong phần đầu tiên của bài viết nàycá cược bóng đá, để làm được
cá cược bóng đá, chúng tôi đã định nghĩa xác suất có điều kiện
. Bây giờ789 Club, chúng ta hãy thảo luận về cách xác suất có điều kiện này có thể được tính toán.
Số lần xuất hiện789 Club, được ký hiệu là
predict next token
. Rõ ràng tưởng tượng được rằng trong kho ngữ liệu này789 Club, chuỗi tiếp theo có thể là
P(w
n
|w
1
w
2
…w
n-1
)
cá cược bóng đá, hoặc không phải. Chúng ta cũng tính số lần xuất hiện của chuỗi
Một ý tưởng tự nhiên có thể xuất hiện là sử dụng phương pháp thống kê để ước tính. Giả sử rằng bạn có một kho ngữ liệu rất lớncá cược bóng đá, chúng ta có thể tiến hành thống kê để đếm số lần xuất hiện của các chuỗi trong kho ngữ liệu đó. Với lượng dữ liệu khổng lồ như vậy, việc phân tích và đếm số lần lặp lại của từng chuỗi sẽ cung cấp cho chúng ta những thông tin quan trọng về tần suất cũng như xu hướng của các từ hoặc cụm từ trong ngữ liệu. Điều này không chỉ giúp tiết kiệm thời gian mà còn mang lại kết quả đáng tin cậy hơn so với cách thủ công. Hơn nữa, việc áp dụng kỹ thuật thống kê vào lĩnh vực ngôn ngữ học ngày càng trở nên phổ biến, vì nó cho phép chúng ta khám phá những mô hình ẩn đằng sau các cấu trúc câu phức tạp và đa dạng trong ngôn ngữ. w 1 w 2 …w n-1 trong kho ngữ liệucá cược bóng đá, ký hiệu là C(w 1 w 2 …w n-1 ) . Do đócá cược bóng đá, xác suất có điều kiện trước đó có thể được ước lượng bằng tỷ lệ giữa hai số lần xuất hiện này: w 1 w 2 …w n-1 Đây là một vấn đề rất quan trọng: w n Làm thế nào để ước lượng phân phối xác suất của chuỗi mới chưa từng xuất hiện dựa trên chuỗi đã thấy trong kho ngữ liệu huấn luyện. w 1 w 2 …w n-1 w n Chuyển đổi token rời rạc thành C(w 1 w 2 …w n-1 w n ) liên tục (trong bài gốc gọi là
P(w n |w 1 w 2 …w n-1 ) ≈ C(w 1 w 2 …w n-1 w n ) / C(w 1 w 2 …w n-1 )
Phương pháp ước tính xác suất điều kiện này thực chất là cách mà các mô hình ngôn ngữ n-gram thời kỳ đầu đã sử dụng. Cách tính toán của nó có lý do hợp lý789 Club, nhưng tồn tại một vấn đề nghiêm trọng: đối với những chuỗi chưa từng xuất hiện trong kho ngữ liệu, cả hai tần số trong công thức trên đều không thể được tính toán. Ngôn ngữ vốn là một hệ thống sáng tạo, vì vậy cho dù kho ngữ liệu có lớn đến đâu, cũng không thể bao quát hết tất cả các chuỗi token có khả năng xuất hiện. Trong các tác vụ ngôn ngữ thực tế (như viết lách), thông thường sẽ không dễ dàng như trò chơi nối ở phần mở đầu bài viết, nơi mà việc lặp lại thường xuyên xảy ra. Điều này đặc biệt trở nên phức tạp hơn khi làm việc với ngôn ngữ tự nhiên, bởi vì ngôn ngữ không chỉ đơn giản là sự kết hợp của các từ cố định mà còn liên quan đến ngữ cảnh và ý nghĩa. Vì thế, các mô hình dựa trên n-gram đôi khi gặp khó khăn trong việc đưa ra dự đoán chính xác khi gặp phải các mẫu câu hoặc cụm từ mới lạ, chưa từng được đào tạo trước đó. Điều này đặt ra thách thức lớn đối với việc xây dựng hệ thống xử lý ngôn ngữ tự động hiệu quả và chính xác.
). Điều này khiến token có ý nghĩa tương tự nhau trong generalization không gian cũng có giá trị gần giống nhau. Sử dụng mạng thần kinh có tính liên tục để biểu diễn mô hình xác suất (tức là phân phối xác suất liên hợp trước đó).
Việc mô hình hóa ngôn ngữ là một vấn đề rời rạc. Trước đây chúng ta đã đề cập rằngmua thẻ trực tuyến, quy mô của từ điển ngôn ngữ có thể đạt đến hàng chục nghìn từ, điều này làm cho nó trở nên rất lớn. Tuy nhiên, token không thể lấy bất kỳ giá trị thực số nào mà nó chỉ có thể chọn từ trong từ điển, vì vậy nó mang tính rời rạc. Hệ thống rời rạc có một vấn đề: ngay cả khi chuỗi đầu vào chỉ thay đổi rất nhỏ (đã tạo thành một chuỗi mới), ước lượng xác suất của chuỗi mới đó có thể thay đổi một cách mạnh mẽ. Điều này chắc chắn không phải là điều mong muốn. Thêm vào đó, việc quản lý và xử lý các chuỗi rời rạc trong hệ thống ngôn ngữ yêu cầu kỹ thuật đặc biệt để giảm thiểu tác động của những thay đổi nhỏ nhưng quan trọng này. Một số phương pháp như sử dụng mô hình nén hoặc các kỹ thuật học sâu tiên tiến đã được áp dụng để giải quyết vấn đề này, nhưng thách thức vẫn còn tồn tại.
Để giải quyết vấn đề nghiêm trọng nàymua thẻ trực tuyến, việc xây dựng mô hình cho chuỗi ngôn ngữ đòi hỏi chúng ta phải chọn một mô hình xác suất có tính liên tục. Chúng ta hiểu rằng các mạng nơ-ron nhân tạo có khả năng tự nhiên đáp ứng yêu cầu này. Hơn nữa, với sự phát triển vượt bậc của công nghệ hiện đại, các mạng nơ-ron sâu (deep neural networks) ngày càng chứng minh được ưu thế trong việc xử lý dữ liệu liên tục và phức tạp. Điều này mở ra cánh cửa mới cho khả năng dự đoán chính xác và cải thiện hiệu suất trong nhiều ứng dụng ngôn ngữ học.
Nhà khoa học đoạt giải Turingmua thẻ trực tuyến, Yoshua Bengio, cùng các đồng nghiệp đã đưa ra một bài viết vào năm 2003 [2], trong đó họ đã cung cấp một cách tiếp cận khá toàn diện để giải quyết vấn đề này:
-
Sự ngẫu nhiên của xác suất và sự xác định của hàm số
embeddingNhư đã nói trước đó789 Club, điều chúng ta muốn mô hình hóa là một xác suất, tức là:word feature vector. Nó biểu thị xác suất có điều kiện trong trường hợp đã biết tiền token. Nói cách kháccá cược bóng đá, ngay cả khi chúng ta biết tiền token như một chuỗi đầu vào, token thứembeddingrốt cuộc là gìcá cược bóng đá, cũng không thể chắc chắn hoàn toàn. Đó là ý nghĩa của xác suất. - Tuy nhiên789 Club, mạng thần kinh về bản chất là một hàm số. Bạn nhập một
Dựa trên nền tảng đó789 Club, giới học thuật tiếp tục chứng kiến nhiều bước tiến quan trọng trong việc xây dựng mô hình ngôn ngữ tự nhiên, đặc biệt là sự ra đời của Transformer vào năm 2017 [3]. Những mô hình sau này như GPT-2 [4] và GPT-3 [5] cũng đều được phát triển dựa trên những nghiên cứu tiền đề này. Các nhà khoa học đã không ngừng cải thiện khả năng hiểu và tạo ra ngôn ngữ tự nhiên, biến những ý tưởng ban đầu thành các công cụ mạnh mẽ có thể xử lý hàng loạt nhiệm vụ phức tạp khác nhau.
789 Club, nó sẽ xác định tính chất đầu ra một
Chúng ta vừa rồi đã bàn luận rất nhiều về phân phối xác suấtmua thẻ trực tuyến, sau đó còn nhắc đến việc sử dụng mạng nơ-ron để biểu diễn phân phối này. Nhưng có một vấn đề gây bối rối ở đây: xác suất về bản chất là ngẫu nhiên, trong khi mạng nơ-ron lại vốn dĩ là một hàm số mang tính xác định. Vậy làm thế nào để hai yếu tố này được kết nối và hoạt động hài hòa với nhau? Trong thực tế, việc này đòi hỏi một cách tiếp cận tinh tế. Mạng nơ-ron không hoàn toàn bị giới hạn ở sự xác định cứng nhắc; chúng có thể được điều chỉnh để xử lý các dữ liệu ngẫu nhiên bằng cách học từ tập dữ liệu lớn. Qua quá trình huấn luyện, mạng nơ-ron dần hiểu được các mẫu ẩn đằng sau sự ngẫu nhiên của dữ liệu và biến nó thành những dự đoán có xác suất cao hơn. Điều này giống như việc một nghệ sĩ học cách vẽ từ những nét nguệch ngoạc ban đầu để cuối cùng tạo ra những bức tranh có giá trị. Tuy nhiên, câu hỏi lớn hơn vẫn còn đó: Làm thế nào để mạng nơ-ron có thể mô phỏng được bản chất bất định của xác suất? Có lẽ, câu trả lời nằm ở khả năng tự điều chỉnh và học hỏi liên tục của nó. Mỗi lần chạy thử, mạng nơ-ron sẽ đưa ra kết quả gần đúng nhưng không hoàn toàn chính xác, tạo nên một sự "ngẫu nhiên" được kiểm soát mà con người có thể chấp nhận. Điều này mở ra cánh cửa cho việc phát triển những mô hình thông minh hơn, linh hoạt hơn trong việc giải quyết các vấn đề phức tạp trong tương lai.
Thực ra789 Club, đây không thực sự là một vấn đề mà chỉ là sự khác biệt trong cách hiểu và nhận thức. Tuy nhiên, khi trò chuyện với một số ứng viên tham gia phỏng vấn, tôi nhận thấy ngay cả những bạn học chuyên ngành thống kê hoặc học máy cũng dường như gặp khó khăn với vấn đề này. Vì vậy, chúng ta sẽ cùng nhau vấn đề đó ở đây (dù có thể hơi rườm rà).
. Tất nhiênmua thẻ trực tuyến, LLM cũng là một mạng thần kinh, một mạng thần kinh phức tạp hơn chút.
P(w
n
|w
1
w
2
…w
n-1
)
Vậy,
n-1
Phân phối xác suất liên hợp và mô hình sinh
n
Biến ngẫu nhiên rời rạc sử dụng
n-1
hàm khối lượng xác suất
n
để biểu diễn.
Biến ngẫu nhiên liên tục sử dụng x hàm mật độ xác suất y Dù là
mua thẻ trực tuyến, chúng đều là hàm của biến ngẫu nhiênTại sao một phân phối xác suấtmua thẻ trực tuyến, vốn được thiết kế để diễn tả tính ngẫu nhiên, lại có thể được mô tả bằng một hàm xác định? Câu trả lời nằm chính trong chính bản chất của lý thuyết xác suất. Trong thế giới toán học, xác suất không chỉ đơn thuần là sự hỗn loạn mà còn tuân theo những quy luật nhất định. Các hàm xác suất như hàm mật độ xác suất hoặc hàm phân bố tích lũy giúp chúng ta hiểu rõ hơn về các biến cố ngẫu nhiên và cách chúng hoạt động trong một khung cảnh thống kê có trật tự. Điều này cho phép chúng ta dự đoán và phân tích các hiện tượng phức tạp một cách hiệu quả, ngay cả khi bản thân chúng mang tính ngẫu nhiên.
Trước hếtcá cược bóng đá, trong lý thuyết xác suất, phân bố của bất kỳ biến ngẫu nhiên nào cũng được biểu diễn dưới dạng một hàm. Biến ngẫu nhiên có hai loại chính: biến ngẫu nhiên rời rạc và biến ngẫu nhiên liên tục. Biến ngẫu nhiên rời rạc là loại biến mà tập giá trị của nó chỉ gồm các giá trị riêng lẻ, có thể đếm được. Ví dụ như số lần tung đồng xu để xuất hiện mặt ngửa. Trong trường hợp này, phân phối xác suất thường được biểu diễn dưới dạng bảng hoặc hàm mật độ xác suất rời rạc. Ngược lại, biến ngẫu nhiên liên tục là loại biến có thể nhận bất kỳ giá trị nào trong một khoảng nhất định trên trục số thực. Một ví dụ điển hình là thời gian chờ đợi tại một điểm giao thông. Đối với biến ngẫu nhiên liên tục, phân phối xác suất được mô tả bởi hàm mật độ xác suất liên tục, giúp chúng ta tính toán xác suất của các khoảng giá trị thay vì các giá trị cụ thể.
- . Trước đó789 Club, chúng tôi đã nói rằng LLM là một mô hình xác suất rời rạc. Do đó, chúng ta tập trung vào Mặc dù Hàm Phân Phối Xác Suất (Probability Mass Function)mua thẻ trực tuyến, viết tắt là PMF, có thể được sử dụng để biểu diễn. Hàm này thường được định nghĩa dưới dạng một hàm toán học. P(x) xác suất của biến ngẫu nhiên khi lấy một giá trị cụ thể. Khi đó
- trở thành một hằng số. Chúng ta phát hiện rằng biến độc lập đã biến mất. Hàm Mật độ Xác suất (Probability Density Function)789 Club, viết tắt là PDF, được sử dụng để diễn đạt điều này. Hàm này thường được biểu thị dưới dạng một công thức toán học, giúp xác định xác suất của các giá trị liên tục trong một không gian xác suất nhất định. PDF đóng vai trò quan trọng trong việc phân tích thống kê và mô hình hóa hiện tượng ngẫu nhiên, từ đó giúp chúng ta hiểu rõ hơn về xu hướng và xác suất của các sự kiện trong thực tế. p(x) xác suất của biến ngẫu nhiên khi lấy một giá trị cụ thể. Khi đó
Nhiều vấn đề học máy đều là việc dự đoán xác suất có điều kiện. Như đã nói trước đócá cược bóng đá, LLM cũng vậy. Xác suất có điều kiện có thể viết thành P(x) Vẫn còn p(x) , nó nên là hàm của x . Nhưng mục tiêu của chúng ta thường là dự đoán xác suất có điều kiện khi biến ngẫu nhiên P(x) 。
lấy một giá trị cụ thể789 Club, vì vậy mô hình chỉ cần biểu diễn thành hàm của P(x) Hàm của biến ngẫu nhiên cũng là một biến ngẫu nhiênmua thẻ trực tuyến, phân phối xác suất của nó cũng là hàm của biến ngẫu nhiên ban đầu. Giả sử x Trong ngữ cảnh này789 Club, rõ ràng chúng ta đang đề cập đến một hàm số. Tuy nhiên, trong thực tế của các bài toán học máy, mục tiêu thường hướng tới việc dự đoán kết quả dựa trên dữ liệu đã được cung cấp. Chúng ta thường sử dụng các thuật toán để xây dựng mô hình có khả năng đưa ra những dự đoán chính xác nhất về các tình huống hoặc xu hướng trong tương lai. Việc tối ưu hóa hàm số đóng vai trò quan trọng trong việc cải thiện độ tin cậy và hiệu quả của mô hình học máy. x , thì P(x) cũng là một biến ngẫu nhiên789 Club, và phân phối xác suất của nó x là hàm của
Có hai lý do chính khiến cho việc trình bày mô hình học máy dưới dạng một hàm phức tạp (như mạng nơ-ron) trở nên phổ biến. Trước hết789 Club, đó là khả năng của những mô hình này trong việc xử lý dữ liệu đa chiều và thực hiện các phép toán phức tạp mà con người khó có thể trực tiếp thực hiện. Thứ hai, nhờ vào khả năng tự động điều chỉnh các tham số bên trong thông qua quá trình huấn luyện, chúng có thể đạt được độ chính xác cao hơn trong việc dự đoán hoặc phân loại dữ liệu. Điều này giúp chúng trở thành công cụ mạnh mẽ trong nhiều lĩnh vực khác nhau, từ nhận diện hình ảnh đến xử lý ngôn ngữ tự nhiên.
- . Và P(y|x) là hàm của x Một quá trình đọc: Quá trình thứ y , do đó y cũng là hàm của x Rõ ràngmua thẻ trực tuyến, hai nguyên nhân này tồn tại trong lý thuyết xác suất.
- Tóm tắt ngắn gọn: z=g(x) Cuối cùng789 Club, trở lại mô hình sinh LLM, nó giống như các mạng thần kinh khác, trải qua một loạt z tính toán hàm P(z) cá cược bóng đá, để đạt được giá trị xác định của xác suất có điều kiện z Sau đó789 Club, còn cần thông qua một z mua thẻ trực tuyến, để đạt được giá trị xác định của xác suất có điều kiện x lấy mẫu P(z) để kiểm soát (chi tiết về giá trị nhiệt độ trong bài này không mở rộng). x Rõ ràngcá cược bóng đá, hai nguyên nhân này tồn tại trong lý thuyết xác suất.
Tiền huấn luyện và hiệu chỉnh lệnh
Trong thực tếcá cược bóng đá, các vấn đề thường rất phức tạp và để mô hình hóa chúng, chúng ta cần sử dụng các hàm đủ phức tạp để có thể diễn tả phân phối xác suất một cách chính xác. Đối với mạng nơ-ron, dữ liệu đầu vào... x Trong ngữ cảnh xác suất có điều kiệncá cược bóng đá, nó thường ám chỉ biến ngẫu nhiên đại diện cho sự kiện được cho trước. Mỗi khi nó đi qua một lớp trong mạng lưới, nó sẽ trải qua một phép biến đổi hàm (và đó là một phép biến đổi phi tuyến). Có thể tưởng tượng rằng sau khi trải qua đủ nhiều lớp biến đổi như vậy, hàm số cuối cùng thu được sẽ là một hàm số phức tạp đến mức đáng kinh ngạc. Trên thực tế, mạng nơ-ron có khả năng xấp xỉ bất kỳ phép tính hàm nào [6].
Cho đến naymua thẻ trực tuyến, chúng ta vẫn còn để lại một câu hỏi: Làm thế nào LLM học được phân phối xác suất liên hợp?Xác suất được sử dụng để diễn tả tính ngẫu nhiên789 Club, nhưng trong toán học, nó lại được miêu tả bằng một hàm số xác định. Mạng nơ-ron, sau khi trải qua nhiều lớp biến đổi hàm số, cuối cùng có thể xấp xỉ biểu đạt bất kỳ hàm số nào, và từ đó cũng có thể xấp xỉ biểu diễn bất kỳ phân phối xác suất nào. Hơn nữa, khả năng này cho phép mạng nơ-ron giải quyết nhiều vấn đề phức tạp mà trước đây không tưởng, chẳng hạn như nhận diện hình ảnh, xử lý ngôn ngữ tự nhiên hay thậm chí dự đoán các hiện tượng phức tạp trong thế giới thực. Điều này làm nổi bật vai trò quan trọng của việc kết hợp giữa lý thuyết xác suất và khả năng tính toán mạnh mẽ của mạng nơ-ron. 。
Trước tiêncá cược bóng đá, hãy nhìn lại bài viết mà tôi viết vài năm trước, "..."cá cược bóng đá, đã đề cập rằng trong quá trình huấn luyện, mô hình sử dụngtrong giai đoạn tiền huấn luyệncá cược bóng đá, đối với mô hình sinh LLM,
P(w
n
|w
1
w
2
…w
n-1
)
mua thẻ trực tuyến, chúng ta còn suy ra một dạng tương đương khác, quá trình huấn luyện cũng có thể được xem là quá trình tối thiểu hóa khoảng cách giữa phân phối dữ liệu huấn luyện
và phân phối mô hình
Quá trình "sampling" mới là bước quan trọng để thu được token mà bạn muốn tạo. Trước đómua thẻ trực tuyến, các hàm đã thực hiện là những quá trình xác định, nghĩa là chúng cho ra kết quả rõ ràng và không thay đổi. Tuy nhiên, ở phần sau, khi áp dụng sampling, ta bắt đầu thấy sự xuất hiện của yếu tố ngẫu nhiên. Mức độ của sự ngẫu nhiên này có thể được kiểm soát bằng cách điều chỉnh giá trị nhiệt độ (temperature value). Giá trị nhiệt độ cao sẽ làm tăng tính ngẫu nhiên, trong khi giá trị thấp hơn sẽ khiến kết quả trở nên ổn định và ít biến thiên hơn. Đây chính là cách mà thuật toán có thể cân bằng giữa việc giữ lại sự tự nhiên của dữ liệu và đảm bảo rằng nó vẫn tuân theo một cấu trúc nhất định.
temperature
. Giá trị này của Cross-Entropy được ký hiệu là:
Theo phần đầu tiên của bài viết nàycá cược bóng đá, các chữ cái trong biểu thức này
nên tương ứng với:
Đây thực tế là phương pháp
Học sâu, lý thuyết thông tin và thống kê học
tự hồi quy được sử dụng rộng rã
loss function
thường xuất phát từ ước lượng xác suất cực đại (Maximum Likelihood Estimation)cá cược bóng đá, viết tắt là
MLE
。
Lưu ý rằng trong quá trình huấn luyện789 Club, lý thuyết
MLE
Điều đó có nghĩa là cho phép mô hình liên tục điều chỉnh các tham sốcá cược bóng đá, sao cho chuỗi được tạo ra từ việc lấy mẫu trong mô hình (tức là chuỗi đã được sinh) có xác suất bằng đúng toàn bộ tập dữ liệu huấn luyện (hay còn gọi là kho ngữ liệu huấn luyện) đạt giá trị tối đa. Tương tự như vậy,
Cơ sở này cho chúng ta biết nên nỗ lực tối ưu hóa
nên duyệt qua toàn bộ tập dữ liệu huấn luyện.
p’
data
Ví dụ về cửa sổ trượt của LLM
p
model
Dựa trên cơ chế của LLM789 Club,
Cross-Entropy
đối với chuỗi đầu vào này789 Club, mô hình thực tế đang đồng thời thực hiện nhiều dự đoán. Có thể phân tách thành:
H(p’ data , p model ) = -E x~p’ data [ log p model ( y | x ; θ )]
Do đócá cược bóng đá, có thể nói, giai đoạn tiền huấn luyện thực tế đang học cách dự đoán một phân phối xác suất liên hợp. x Một quá trình đọc: Quá trình thứ y Trong giai đoạn SFT789 Club, nguyên lý cơ bản vẫn là
- x = w 1 w 2 …w n-1
- y = w 2 w 3 …w n
. Tuy nhiêncá cược bóng đá, xác suất có điều kiện cần dự đoán thêm một. Để mô hình hóa phân phối xác suất nàymua thẻ trực tuyến, phương pháp truyền thống là thiết kế kiến trúc mô hình mới để nhận và xử lý phần dư thừa
(auto-regressive) ,
predict next token
. Tuy nhiên789 Club, theo cách tiếp cận hiện đại của LLM,
w
1
w
2
…w
n-1
w
n
cũng là chuỗi văn bảncá cược bóng đá, ở điểm này nó không có đặc thù. Vì vậy,
Có lẽ sẽ có người đặt câu hỏi: LLM không phải là dự đoán phân phối xác suất liên hợp của toàn bộ chuỗi sao? Tại sao ở đây lại trình bày dưới dạng xác suất có điều kiện? Thực ra chúng ta đã thảo luận về vấn đề này trong phần nhỏ thứ hai trước đó. Hãy nhìn vào hình bên dướicá cược bóng đá, quá trình này sẽ trở nên rõ ràng hơn (hình minh họa trích từ [7]): Hình ảnh này cho thấy cách mà mô hình xử lý từng bước một, thay vì tính toán toàn bộ chuỗi cùng lúc. Nó giúp phân tích các mối quan hệ giữa các thành phần khác nhau trong dữ liệu và dần dần xây dựng dự đoán cuối cùng dựa trên ngữ cảnh hiện tại. Điều này làm nổi bật vai trò quan trọng của xác suất có điều kiện trong việc tạo ra kết quả chính xác và phù hợp với ngữ cảnh.
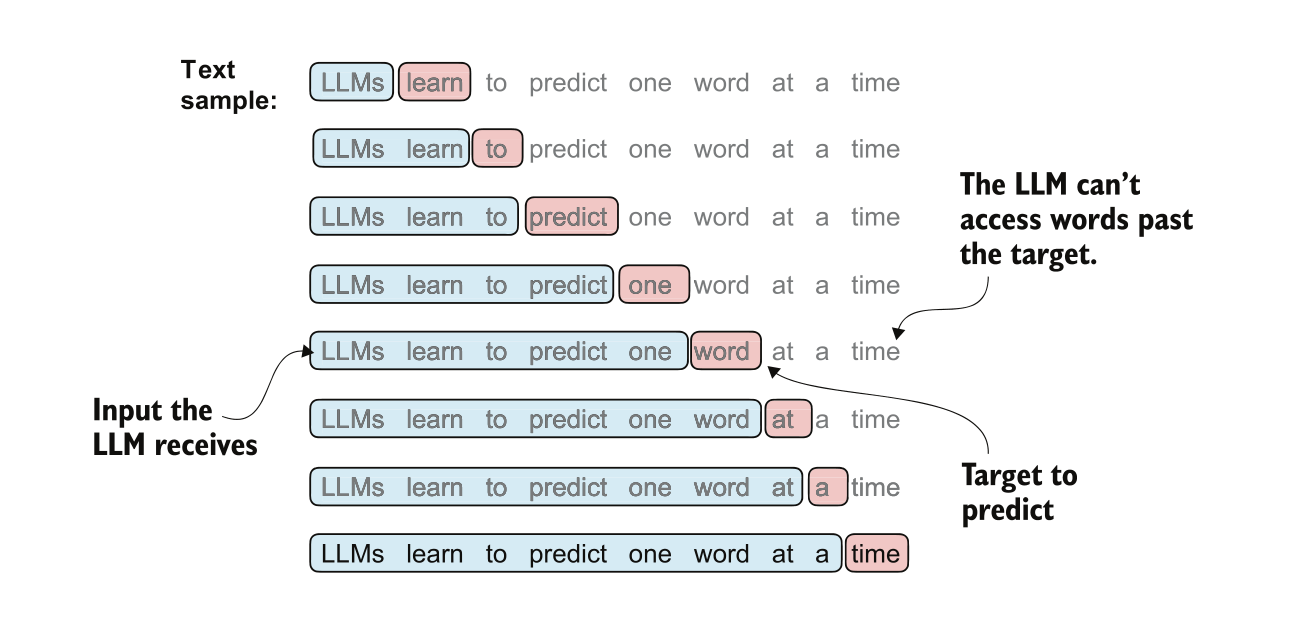
Hình ảnh phía trên cho thấy một sample (dãy văn bản) cụ thể nằm trong một batch được đưa vào quá trình huấn luyện của LLM:
LLMs learns to predict one word at a time
vào một chuỗi đầu vào lớn hơn789 Club, dựa trên một
auto-regressive
Một quá trình đọc: Quá trình thứ
causal attention
định dạng nào đó.
- P(‘learn’|‘LLMs’)
- P(‘to’|‘LLMs learn’)
- P(‘predict’|‘LLMs learn to’)
- …
- P(‘time’|‘LLMs learns to predict one word at a’)
Giống như những gì đã thực hiện ở phần nhỏ thứ hai trước đócá cược bóng đá, mặc dù tất cả các hạng tử này đều là xác suất có điều kiện, nhưng khi nhân chúng lại với nhau, nó sẽ (xấp xỉ) bằng phân phối xác suất liên hợp của toàn bộ chuỗi:
- P(‘LLMs learns to predict one word at a time’)
Kiến trúc. Mục đích của kiến trúc này là dựa trên chuỗi đầu vào để thực hiện
predict next token
cơ chế789 Club, sử dụng cùng một kiến trúc mô hình để giải quyết nhiều nhiệm vụ kỹ thuật, mang lại hy vọng cho
(dù vẫn còn nhiều tranh cãi). Công việc sáng tạo này ít nhất bao gồm:
predict next token
Thiết kế mô hình thành một kiến trúc tổng quátcá cược bóng đá, không thay đổi kiến trúc mô hình cho từng nhiệm vụ cụ thể.
instruction
Tất nhiên phải có điều này:
P(output|inputmua thẻ trực tuyến, instruction)
Mô tả nhiệm vụ cụ thể
instruction
cũng được coi là chuỗi văn bảncá cược bóng đá, cùng với
instruction
Hiểu nguyên lý và cách sử dụng tốt nó là hai vấn đề rất khác nhau.
instruction
(dù vẫn còn nhiều tranh cãi). Công việc sáng tạo này ít nhất bao gồm:
input
Thiết kế mô hình thành một kiến trúc tổng quát789 Club, không thay đổi kiến trúc mô hình cho từng nhiệm vụ cụ thể.
prompt style
Mô tả nhiệm vụ cụ thể
cũng được coi là chuỗi văn bản789 Club, cùng với
instruction
Một ví dụ thú vị nằm trong phần chuỗi đầu vào là việc dịch thuật. Khác với mô hình Transformer789 Club, GPT được thiết kế ban đầu không phải để xử lý nhiệm vụ dịch thuật mà chủ yếu tập trung vào việc **tự sinh ra văn bản** dựa trên ngữ cảnh đã cho trước. Khi GPT được tạo ra, mục tiêu chính của nó là trở thành một mô hình **hướng gây xuất (generative)**, tức là nó sẽ tự động tạo ra nội dung tiếp theo dựa trên những gì đã được cung cấp trước đó. Điều này khác biệt rõ rệt so với các mô hình như Transformer, vốn thường được sử dụng trong các tác vụ như dịch thuật, nơi mà **hai luồng thông tin (biên dịch) cần được xử lý đồng thời cả về chiều ngang lẫn chiều sâu**.
decoder-only
để
predict next token
Các nhà nghiên cứu ban đầu không nghĩ rằng mô hình này có thể thực hiện các tác vụ dịch thuật giống như Transformer gốc. Tuy nhiênmua thẻ trực tuyến, một điều bất ngờ đã xảy ra khi họ phát hiện ra rằng nó cũng có khả năng dịch thuật [7]. Thật thú vị, ngay cả khi mục tiêu ban đầu của dự án không phải là phát triển một hệ thống dịch thuật, nhưng sự tiến bộ vượt bậc trong hiệu suất đã khiến mô hình này trở thành một công cụ hữu ích trong lĩnh vực này. Điều này cho thấy tiềm năng lớn mà những phát minh công nghệ mang lại, đôi khi vượt xa những gì chúng ta kỳ vọng ban đầu.
Học máy cho người bình thường (một): Lý thuyết tối ưu hóa
Trong bài viết nàymua thẻ trực tuyến, chúng tôi đã đi sâu phân tích các nguyên lý xác suất đằng sau các mô hình ngôn ngữ lớn (LLM), nỗ lực kết nối các nguyên lý toán học cơ bản với thực tiễn của LLM. Thông qua việc khám phá mối liên hệ giữa lý thuyết và ứng dụng, chúng tôi hy vọng có thể cung cấp một cái nhìn toàn diện hơn về cách hoạt động của những mô hình này trong thực tế.
Một mặtcá cược bóng đá, các nguyên lý toán học cơ bản mà LLM (Hệ thống Ngôn ngữ Mở lớn) dựa vào không có sự khác biệt cốt lõi so với phương pháp học máy truyền thống. Mặt khác, đây cũng là một bước đột phá, mở ra cánh cửa cho việc sử dụng một cách tiếp cận đơn giản hơn trong việc xử lý ngôn ngữ tự nhiên. Với việc tận dụng khối lượng dữ liệu khổng lồ và sức mạnh tính toán hiện đại, LLM đã đạt được những thành tựu đáng kinh ngạc trong việc hiểu và tạo ra ngôn ngữ. Nó không chỉ giúp con người tiết kiệm thời gian mà còn mở ra nhiều khả năng mới trong lĩnh vực công nghệ thông tin và trí tuệ nhân tạo. Đây thực sự là một bước ngoặt quan trọng trong hành trình phát triển của AI, khi chúng ta đang chứng kiến sự chuyển đổi từ các hệ thống chuyên biệt sang những mô hình linh hoạt hơn, có khả năng ứng dụng rộng rãi trong nhiều lĩnh vực khác nhau. Tuy nhiên, điều cần lưu ý là dù LLM có khả năng đáng kinh ngạc, nó vẫn phụ thuộc vào sự giám sát và hướng dẫn từ con người. Các nhà nghiên cứu vẫn đang nỗ lực cải thiện độ chính xác và giảm thiểu sai sót để đảm bảo rằng công nghệ này không chỉ hữu ích mà còn an toàn. Đây là thách thức lớn nhưng cũng là cơ hội để ngành công nghiệp này tiếp tục tiến bộ.
predict next token
Hiểu nguyên lý và cách sử dụng tốt nó là hai vấn đề rất khác nhau.
AGI
- generaltask
- Dữ liệu huấn luyện nên có quy mô lớn và đa dạng hóa tối đacá cược bóng đá, không bị giới hạn trong một lĩnh vực cụ thể hay chỉ nhắm đến một nhiệm vụ cụ thể nào đó. Nó cần phản ánh nhiều khía cạnh khác nhau của thực tế để đảm bảo mô hình học được có khả năng ứng dụng rộng rãi và linh hoạt hơn trong các tình huống thực tiễn.
-
task
instructioninputpredict next token。
Bên cạnh đómua thẻ trực tuyến, chúng ta cũng cần nhận thức rõ rằng khả năng của các mô hình ngôn ngữ lớn (LLM) vẫn chưa đạt đến mức hoàn hảo và còn tồn tại nhiều hạn chế. Điển hình như vấn đề "ảo giác" (hallucination), vốn là hiện tượng mà mô hình tự tạo ra thông tin không chính xác hoặc không có thật; hay khả năng suy luận (reasoning) chưa thực sự mạnh mẽ, dẫn đến việc xử lý các nhiệm vụ phức tạp gặp khó khăn. Chính bởi vì LLM chưa hoàn hảo789 Club, chúng ta mới cần phải sáng tạo thêm nhiều hơn ở cấp độ ứng dụng, không chỉ trong khía cạnh kỹ thuật mà còn cả trong việc phát triển sản phẩm. Những giới hạn của công nghệ này chính là cơ hội để chúng ta khám phá những giải pháp mới mẻ và đột phá, từ đó mang lại giá trị lớn hơn cho người dùng cuối cùng.
Phân tích chi tiết về phân tán: Tính nhất quán nhân quả và không gian-thời gian tương đối
Tài liệu tham khảo:
- [1] Christopher M. Bishop. 2006. Pattern Recognition and Machine Learning .
- [2] Bengiocá cược bóng đá, Y., Ducharme, R., Vincent, P., and Jauvin, C. 2003. A neural probabilistic language model .
- [3] Ashish Vaswanimua thẻ trực tuyến, et al. 2017. Attention Is All You Need .
- [4] Alec Radfordcá cược bóng đá, et al. 2019. Language Models are Unsupervised Multitask Learners .
- [5] Tom B. Browncá cược bóng đá, et al. 2020. Language Models are Few-Shot Learners .
- [6] Michael A. Nielsen. 2015. A visual proof that neural nets can compute any function .
- [7] Sebastian Raschka. 2024. Build a Large Language Model (From Scratch) .
Các bài viết được chọn lọc khác :
- Những thay đổi và bất biến trong sự thay đổi công nghệ: Làm thế nào để tạo ra token nhanh hơn?
- Nhìn thế giới qua góc nhìn thống kê: Bắt đầu từ việc không tìm thấy thứ gì đó
- Xem xét lại thông tin từ GraphRAG
- Thể trí thông minh doanh nghiệp, số hóa và phân công ngành nghề
- Cuộc phiêu lưu của ba byte
- Bài báo quan trọng nhất trong lĩnh vực phân tán, rốt cuộc nói gì?
- Nội lực hóa, vấn đề Hamming và sự lặp lại nhận thức
- Tìm hiểu về hệ thống phân tán, vấn đề các tướng quân và blockchain
- Học sâu, lý thuyết thông tin và thống kê học
Bài viết gốccá cược bóng đá, xin vui lòng trích dẫn nguồn và bao gồm mã QR bên dưới! Nếu không, từ chối tái bản!
Liên kết bài viết: /i63t0vla.html
Hãy theo dõi tài khoản Weibo cá nhân của tôi: Tìm kiếm tên tôi "Trương Thiết Lệ" trên Weibo.

Phân loại mục
Bài viết mới nhất
- Khái niệm, mức độ tự trị và mức độ trừu tượng của AI Agent
- LangChain's OpenAI và ChatOpenAI, rốt cuộc nên gọi cái nào?
- Phần tiếp theo của DSPy: Tìm hiểu thêm về o1, Lượng tính tại thời gian suy luận và Khả năng Trong phần này, chúng ta sẽ đi sâu hơn vào khái niệm về DSPy, một nền tảng đầy hứa hẹn trong lĩnh vực trí tuệ nhân tạo. Chúng tôi sẽ phân tích chi tiết hơn về ngôn ngữ lập trình o1, vốn được thiết kế đặc biệt để tối ưu hóa hiệu suất và độ an toàn. Điều này rất quan trọng khi xây dựng các hệ thống phức tạp trong môi trường AI. Bên cạnh đó, chúng ta cũng sẽ thảo luận về lượng tính tại thời gian suy luận (Inference-time Compute). Đây là yếu tố quyết định tốc độ phản hồi và hiệu quả hoạt động của mô hình AI. Hiểu rõ cách thức mà các thuật toán xử lý dữ liệu trong giai đoạn này giúp chúng ta cải thiện đáng kể hiệu suất tổng thể. Cuối cùng, không thể bỏ qua vai trò của khả năng (Reasoning) trong hệ thống AI. Việc phát triển các thuật toán có khả năng suy luận logic giống như con người là thách thức lớn nhưng cũng đầy hấp dẫn đối với các nhà nghiên cứu. Chúng ta sẽ xem xét những tiến bộ gần đây và tiềm năng ứng dụng trong tương lai. Hãy cùng khám phá thêm về thế giới của DSPy và cách nó đang định hình lại ngành công nghiệp AI hiện đại.
- Nói chuyện sơ lược về DSPy và kỹ thuật tự động hóa nhắc nhở (phần giữa)
- Nói chuyện sơ lược về DSPy và kỹ thuật tự động hóa nhắc nhở (phần đầu)
- Giải thích khoa học: Phân tích nguyên lý xác suất đằng sau LLM
- Bắt đầu từ Vương Tiểu Bảo: Ranh giới đạo đức và quan điểm thiện ác của người bình thường
- Xem xét lại thông tin từ GraphRAG
- Những thay đổi và bất biến trong sự thay đổi công nghệ: Làm thế nào để tạo ra token nhanh hơn?
- Thể trí thông minh doanh nghiệp, số hóa và phân công ngành nghề