Nói chuyện sơ lược về DSPy và kỹ thuật tự động hóa nhắc nhở (phần đầu)
2024-11-30
Chóe giữa khe đáxem ngoại hạng anh, lửa giữa thạch, thân giữa mộng.
Cuối tuần không cuộnxem ngoại hạng anh, bận rộn trộm lấy nhàn, viết chút kỹ thuật. 。
Cách giao tiếp hiệu quả với mô hình lớn là một môn nghệ thuật.
sử dụng khoa học để phá vỡ ma thuật
Vì nội dung khá dàixem ngoại hạng anh, tôi dự định sẽ chia bài viết thành 2 đến 3 phần khác nhau. Trong phần này, chúng ta sẽ cùng tìm hiểu về các khái niệm cơ bản trong APE và DSPy, đồng thời minh họa cách DSPy hoạt động thông qua một ví dụ cụ thể về chương trình. Điều này sẽ giúp bạn có được cái nhìn trực quan rõ ràng hơn. Ở những phần tiếp theo, tôi sẽ phân tích sự khác biệt giữa DSPy và APE, rút ra những bài học từ cách tiếp cận kỹ thuật tương tự cũng như thảo luận về một số vấn đề tiềm ẩn có thể xảy ra.
Hai loại câu hỏi gợi ý chính
Đối với mỗi vai trò khác nhauxem ngoại hạng anh, ý nghĩa của từ khóa "prompt" có thể sẽ mang một sắc thái riêng. Để dễ dàng thảo luận, chúng ta có thể chia prompt thành hai nhóm chính: Thứ nhất là các prompt mang tính chất gợi ý sáng tạo, thường được sử dụng trong lĩnh vực nghệ thuật hay viết lách. Những loại này thường hướng dẫn người dùng phát triển ý tưởng theo cách tự do và mở, chẳng hạn như “Tạo ra một cảnh hoàng hôn đầy cảm hứng trên một bãi biển hoang vắng” – điều này khuyến khích người thực hiện phóng khoáng trong việc tưởng tượng và sáng tạo. Thứ hai là các prompt mang tính kỹ thuật hoặc chuyên môn, thường xuất hiện trong các ngành công nghệ, lập trình hoặc nghiên cứu. Với nhóm này, prompt có xu hướng cụ thể và rõ ràng hơn, ví dụ như “Hãy nhập một câu lệnh để tìm kiếm tất cả các tệp văn bản đã chỉnh sửa trong tháng này”. Điều này đòi hỏi người sử dụng phải hiểu rõ cấu trúc và ngữ pháp của hệ thống mà họ đang làm việc. Hai nhóm này không chỉ đơn thuần là phân biệt về mục đích sử dụng mà còn phản ánh sự đa dạng trong cách tiếp cận và ứng dụng của prompt trong nhiều lĩnh vực khác nhau.
- Câu hỏi gợi ý chat thông thường 。
- Câu hỏi gợi ý phát triển hệ thống 。
Các gợi ý trò chuyện thông thường là dành cho những người dùng phổ thông. Một người sử dụng sản phẩm mô hình lớn thông qua hình thức trò chuyện cần phải sử dụng ngôn ngữ rõ ràng để mô tả vấn đề của mìnhbắn cá săn thưởng, từ đó mới có thể nhận được câu trả lời như mong đợi. Ví dụ, nếu bạn muốn mô hình lớn giúp viết một bài văn cho học sinh trung học cơ sở, thì lúc này bạn cần phải truyền đạt đầy đủ và rõ ràng tất cả các thông tin liên quan đến bài văn: bối cảnh của bài viết, ý nghĩa mà bạn mong muốn, phong cách diễn đạt, thậm chí là cảnh cụ thể mà bạn muốn miêu tả, cũng như bất kỳ yêu cầu nào khác về việc viết bài. Điều quan trọng là phải đảm bảo rằng mọi thông tin đều được cung cấp một cách logic và dễ hiểu để mô hình lớn có thể đưa ra kết quả tốt nhất.
Nói cách kháccá cược bóng đá, câu hỏi gợi ý chat thông thường là do người dùng tự viết, chỉ cần mô tả rõ nhu cầu cụ thể cho nhiệm vụ hiện tại là được.
Việc phát triển hệ thống lại mang một cách tiếp cận khácbắn cá săn thưởng, hướng đến các nhà phát triển ứng dụng AI (cụ thể là các kỹ sư). Trong quá trình viết mã và xây dựng hệ thống AI, các kỹ sư thường phải phân tích nhiệm vụ của người dùng thành các bước nhỏ hơn. Điều này dẫn đến việc họ cần tương tác với mô hình lớn ở nhiều giai đoạn khác nhau, từ đó sinh ra công việc viết câu lệnh gợi ý (prompt). Ví dụ như phân loại ý định của câu truy vấn người dùng, trích xuất thực thể, mở rộng từ khóa tìm kiếm, tất cả đều là những tình huống phổ biến trong quá trình phát triển ứng dụng AI.
Rõ ràngxem ngoại hạng anh, các gợi ý từ ngữ cho việc phát triển hệ thống khác biệt rất nhiều so với những gợi ý thông thường trong trò chuyện. Chúng được viết bởi các kỹ sư và cần phải tính đến mọi khả năng nhập liệu khác nhau mà người dùng có thể thực hiện trong một tình huống cụ thể. Do đó, các gợi ý từ ngữ cho hệ thống phát triển yêu cầu một thiết kế mang tính hệ thống cao hơn, phải xem xét đủ các trường hợp ngoại lệ và đảm bảo tỷ lệ chính xác ổn định. Mức độ quan trọng của nó tương đương với việc viết mã lập trình.
Chúng ta sẽ thảo luận về APE tiếp theobắn cá săn thưởng, rõ ràng là nó nhắm vào loại thứ hai trong hai loại câu hỏi gợi ý này — câu hỏi gợi ý phát triển hệ thống.
Các khái niệm cơ bản trong APE và DSPy
Trước khi phân tích cụ thể chương trình DSPybắn cá săn thưởng, chúng ta hãy làm rõ một số khái niệm cơ bản về APE và DSPy.
Vậy APE là gì? Nói đơn giảnxem ngoại hạng anh, đó là sử dụng LLM để tự động giúp chúng ta tạo ra các câu hỏi gợi ý.
Vậy câu hỏi đặt ra làxem ngoại hạng anh, làm sao chúng ta có thể biết được rằng các từ khóa do LLM tạo ra có tốt hay không? Nó có đáp ứng đúng những yêu cầu của chúng ta hay không? Do đó, để sử dụng APE, chúng ta cần phải xác định một tiêu chí rõ ràng. Điều quan trọng là chúng ta phải hiểu rằng việc đánh giá chất lượng từ khóa không chỉ dừng lại ở việc kiểm tra xem nó có hợp lý hay không mà còn cần xem xét liệu nó có thực sự liên quan đến mục tiêu cụ thể mà chúng ta đã đề ra hay không. Một số yếu tố cần cân nhắc bao gồm tính chính xác, độ bao quát và khả năng dẫn dắt người dùng đến đúng kết quả mong muốn. Chỉ khi nào có một tiêu chuẩn rõ ràng, chúng ta mới có thể đo lường hiệu quả và tối ưu hóa quá trình tạo từ khóa, từ đó nâng cao trải nghiệm người dùng cũng như đạt được kết quả mong muốn trong mọi hoạt động. metric Dựa trên chỉ số nàybắn cá săn thưởng, chúng ta có thể tự động đánh giá hiệu suất của các cụm từ gợi ý hiện tại đã được tạo ra đến mức nào. Tất nhiên, việc xác định chỉ số không phải là một nhiệm vụ đơn giản, chúng ta sẽ thảo luận về vấn đề này sau.
Vậy với metric nàybắn cá săn thưởng, cụ thể nó sẽ được đánh giá trên tập dữ liệu nào? Để làm rõ vấn đề này, chúng ta cần cung cấp thêm một cái gì đó quan trọng. Chẳng hạn, liệu metric đó có được thiết kế để đo lường hiệu suất trên các tập dữ liệu lớn hay nhỏ? Liệu nó có phù hợp với những loại dữ liệu cụ thể như văn bản, hình ảnh hay âm thanh hay không? Việc hiểu rõ hơn về tập dữ liệu mà metric hoạt động sẽ giúp chúng ta đánh giá chính xác hơn về độ tin cậy và khả năng áp dụng của nó trong thực tế. Do đó, câu trả lời cho câu hỏi này đòi hỏi chúng ta phải bổ sung thêm thông tin chi tiết, chẳng hạn như ví dụ cụ thể hoặc hướng dẫn cụ thể để mọi người có thể dễ dàng kiểm tra và so sánh kết quả. Tập dữ liệu đã được đánh dấu (labelled dataset) Tất nhiênbắn cá săn thưởng, trong thực tế sử dụng, tập dữ liệu này sẽ được chia thành tập huấn luyện, tập xác minh và tập kiểm tra.
APE là một quá trình không ngừng cải tiến. Mỗi khi tạo ra phiên bản mới của một promptxem ngoại hạng anh, nó sẽ dựa trên các chỉ số (metric) để đánh giá trên tập dữ liệu và thu được một điểm số (score). Miễn là phiên bản prompt mới đạt được điểm số cao hơn so với phiên bản cũ, quy trình APE có thể tiếp tục lặp lại quá trình này, từ đó cho ra đời những prompt ngày càng tốt hơn. Quá trình này giống như một nghệ sĩ không ngừng rèn luyện kỹ năng của mình: mỗi lần họ thực hiện một tác phẩm mới, họ luôn tự đặt ra câu hỏi liệu điều đó có tốt hơn phiên bản trước hay không. Và nếu có, họ sẽ tiếp tục thử thách bản thân để nâng cao khả năng. Chính sự kiên nhẫn và khao khát học hỏi này đã biến APE thành một công cụ mạnh mẽ trong việc tối ưu hóa prompt.
đứng trên chân trái và bước bằng chân phải Câu hỏi gợi ý ban đầu (initial prompt) bắn cá săn thưởng, làm điểm xuất phát cho việc tối ưu hóa và lặp lại.
Ngoài raxem ngoại hạng anh, vì trong APE, câu hỏi gợi ý được tạo ra bởi LLM, vì vậy chúng ta cũng cần mộtCâu hỏi gợi ý được sử dụng để tạo ra câu hỏi gợi ý mớicá cược bóng đá, được gọi là meta-prompt Meta-prompt là một khái niệm rất quan trọ
DSPy là một khung công tác mã nguồn mởcá cược bóng đá, bao gồm hầu hết các yếu tố của dự án APE. Tuy nhiên, DSPy không chỉ giới hạn ở việc tái hiện APE; sự khác biệt giữa hai hệ thống này sẽ được và giải thích chi tiết hơn sau khi chúng ta phân tích quá trình thực thi của DSPy, trong phần tiếp theo của bài viết.
Trước khi đi sâu vào phân tích cụ thể về DSPyxem ngoại hạng anh, hãy cùng điểm qua một số khái niệm cốt lõi mà DSPy đã tóm lược lại trong cách tiếp cận của mình. Những khái niệm này không chỉ giúp chúng ta hiểu rõ hơn về cấu trúc tổng thể mà còn tạo nền tảng vững chắc cho việc áp dụng thực tế sau này.
- Module Đơn vị cơ bản cấu thành của một chương trình DSPy là một Module. Một Module có các định nghĩa rõ ràng về đầu vào và đầu racá cược bóng đá, đồng thời nó sẽ gọi LLM để xử lý từ đầu vào đến đầu ra. Một chương trình DSPy thực tế cũng chính là một Module, nhưng bên trong nó có thể chứa nhiều Module con hơn; bộ tối ưu hóa của DSPy có thể tiến hành tối ưu và lặp lại cho nhiều Module cùng thuộc một chương trình DSPy. Tối ưu hóa ở đây chủ yếu liên quan đến việc tối ưu hóa câu lệnh hoặc nội dung gợi ý (prompt), tức là những gì đã được đề cập trước đó dưới tên gọi APE (Adaptation of Prompt Engineering).
- Signature : Mô tả về đầu vào và đầu ra của một Modulebắn cá săn thưởng, điều này tương tự như chữ ký của một hàm. Signature là một khái niệm đặc trư Chúng ta sẽ giải thích chi tiết hơn về điều này khi phân tích sâu ở phần sau.
- Metric : Trước đây chúng ta đã đề cập đến metricbắn cá săn thưởng, trong DSPy, Metric được khái quát hóa thành một hàm (function), hàm này có thể tính toán được điểm số (score) dựa trên đầu ra của một chương trình DSPy và câu trả lời mong đợi đã được đánh dấu sẵn. Có nhiều cách khác nhau để tính toán điểm số này. Hàm Metric không chỉ đơn thuần là việc so sánh kết quả mà còn có thể thực hiện nhiều phép toán phức tạp hơn. Ví dụ như nó có thể đo lường mức độ chính xác của một câu trả lời dựa trên tỷ lệ phần trăm khớp giữa các từ khóa hoặc phân tích sâu hơn về ngữ nghĩa của nội dung. Điều này mang lại sự linh hoạt lớn cho người dùng khi muốn đo lường hiệu suất của chương trình theo những tiêu chí cụ thể. Điểm số cuối cùng có thể phản ánh không chỉ kết quả đúng sai mà còn cả chất lượng và độ tin cậy của giải pháp mà chương trình đưa ra.
- Evaluate : Tính toán từng Metric trên một tập dữ liệu cụ thểcá cược bóng đá, sau đó tổng hợp để tính toán điểm đánh giá tổng thể.
- Optimizer : Tối ưu hóa. Trong DSPycá cược bóng đá, thực hiện tối ưu hóa cụ thể được gọi là Teleprompter Trong suốt quá trình vận hành chương trình DSPycá cược bóng đá, Teleprompter đóng vai trò là trung tâm điều khiển và thúc đẩy việc tối ưu hóa lặp đi lặp lại. Tại mỗi vòng lặp, nó sẽ tham chiếu nhiều nguồn thông tin khác nhau, bao gồm cả nội dung từ chính chương trình, tập dữ liệu, các prompt cũ cùng với điểm đánh giá tương ứng của chúng. Sau khi phân tích toàn diện, Teleprompter sẽ áp dụng một số chiến lược tối ưu hóa để tạo ra những prompt mới cho từng Module riêng lẻ trong cấu trúc tổng thể của DSPy.
Phân tích ví dụ chạy chương trình DSPy
Trong phần nàycá cược bóng đá, chúng ta sẽ cùng tìm hiểu cách một chương trình cụ thể của DSPy hoạt động. Chương trình mà chúng ta sẽ phân tích đến từ tài liệu hướng dẫn chính thức của DSPy: https://dspy.ai/tutorials/rag/ Bạn có thể thấy cách một chương trình RAG điển hình được tối ưu hóa bằng cách sử dụ Chúng ta sẽ lấy chương trình RAG này làm ví dụ và phân tích từng bước chính cũng như nguyên lý hoạt động đằng sau nó. Chương trình RAG này thực sự là một minh chứng cho cách mà các công nghệ hiện đại có thể kết hợp với nhau để tạo ra một hệ thống hiệu quả. Đầu tiênxem ngoại hạng anh, nó tải dữ liệu từ nguồn, tiếp theo là xử lý thông tin đó để chuẩn bị cho việc truy vấn. Sau đó, chương trình sẽ tìm kiếm câu trả lời dựa trên những gì đã được xử lý trước đó và cuối cùng trả về kết quả. Các bước này không chỉ đơn giản là các thao tác kỹ thuật mà còn phản ánh sự phức tạp trong việc xây dựng một hệ thống trí tuệ nhân tạo. Mỗi bước đều cần được tối ưu hóa cẩn thận để đảm bảo rằng hệ thống có thể hoạt động mượt mà và mang lại kết quả chính xác nhất có thể. Chính vì vậy, việc hiểu rõ cơ chế hoạt động của từng phần trong chương trình là vô cùng quan trọng đối với bất kỳ ai muốn nghiên cứu sâu hơn về lĩnh vực này.
Mã khung chương trình như sau:
# Phần 1: Khởi tạo LLMlm
=
dspy
.
LM
(
'openai/gpt-4o-mini'
)
dspy
.
configure
(
lm
=
lm
)
# Phần 2: Khởi tạo tập dữ liệuwith
open
(
'ragqa_arena_tech_500.json'
)
as
f
:
data
=
ujson
.
load
(
f
)
data
=
[
dspy
.
Example
(
**
d
).
with_inputs
(
'question'
)
for
d
in
data
]
random
.
shuffle
(
data
)
trainset
,
valset
,
devset
,
testset
=
data
[:
50
],
data
[
50
:
150
],
data
[
150
:
300
],
data
[
300
:
500
]
# Phần 3: Khởi tạo Metric và Evaluatemetric
=
SemanticF1
()
evaluate
=
dspy
.
Evaluate
(
devset
=
testset
,
metric
=
metric
,
num_threads
=
8
,
display_progress
=
True
,
display_table
=
2
)
# Phần 4: Khởi tạo mô-đun RAG # Mã nguồn cho việc tìm kiếmbắn cá săn thưởng, ở đây được lược bỏ Chúng ta sẽ bắt đầu bằng cách thiết lập các thành phần cốt lõi của mô-đun RAG. Việc tìm kiếm tài liệu phù hợp từ cơ sở dữ liệu lớn là một bước quan trọng trong quá trình này. Đầu tiên, hãy tưởng tượng rằng chúng ta đang xây dựng một hệ thống tìm kiếm thông minh có khả năng trả lời bất kỳ câu hỏi nào mà người dùng đặt ra. Để thực hiện điều này, trước tiên cần khởi tạo một đối tượng mô-đun RAG với các tham số cụ thể. Những tham số này bao gồm các thông tin về vector embeddings, nơi lưu trữ dữ liệu và các mô hình ngôn ngữ được sử dụng để tinh chỉnh kết quả tìm kiếm. Tiếp theo, chúng ta cần xác định chiến lược tìm kiếm phù hợp. Điều này có thể bao gồm việc sử dụng các thuật toán tối ưu như FAISS hoặc ElasticSearch để tăng tốc độ tìm kiếm. Mỗi thuật toán đều có ưu nhược điểm riêng, do đó cần lựa chọn kỹ lưỡng dựa trên yêu cầu cụ thể của hệ thống. Sau khi đã có cấu hình hoàn chỉnh, chúng ta tiến hành kiểm tra tính hiệu quả của mô-đun bằng cách thực hiện một loạt các thử nghiệm nhỏ. Điều này giúp đảm bảo rằng hệ thống hoạt động đúng cách và sẵn sàng xử lý các yêu cầu phức tạp hơn trong tương lai. Tóm lại, việc khởi tạo mô-đun RAG đòi hỏi sự chuẩn bị kỹ lưỡng về mặt công nghệ cũng như hiểu biết sâu sắc về nhu cầu của người dùng. Bằng cách làm việc chặt chẽ với các nhà phát triển khác, chúng ta có thể tạo ra một hệ thống mạnh mẽ và đáng tin cậy.class
RAG
(
dspy
.
Module
):
def
__init__
(
self
,
num_docs
=
5
):
self
.
num_docs
=
num_docs
self
.
respond
=
dspy
.
ChainOfThought
(
'contextbắn cá săn thưởng, question -> response')
def
forward
(
self
,
question
):
context
=
search
(
question
,
k
=
self
.
num_docs
)
return
self
.
respond
(
context
=
context
,
question
=
question
)
rag
=
RAG
()
score_before_optimization
=
evaluate
(
rag
)
Bước tiếp theo là khởi động Teleprompter và hoàn tất quá trình biên dịch/tối ưu hóa. Hãy nhớ rằngxem ngoại hạng anh, dspy.MIPROv2 thực chất chỉ là một phần nhỏ, hay nói cách khác là một tập con của Teleprompter, giúp định hình cấu trúc cơ bản cho hệ thống này. Quá trình khởi tạo Teleprompter đòi hỏi sự cẩn trọng và chính xác, bởi nó đóng vai trò quan trọng trong việc quản lý nội dung cũng như điều hướng các thông điệp cần hiển thị. Khi được tích hợp đầy đủ, dspy.MIPROv2 sẽ đảm nhận trách nhiệm hỗ trợ các chức năng thiết yếu, từ việc phân tích văn bản đến điều chỉnh tốc độ đọc sao cho phù hợp với người dùng. Đồng thời, việc tối ưu hóa và kiểm tra tính nhất quán giữa dspy.MIPROv2 và toàn bộ hệ thống Teleprompter là bước không thể thiếu. Điều này giúp đảm bảo rằng mọi thành phần đều hoạt động trơn tru, mang lại hiệu suất cao và trải nghiệm ổn định cho người sử dụng cuối.tp
=
dspy
.
MIPROv2
(
metric
=
metric
,
auto
=
"light"
,
num_threads
=
8
)
optimized_rag
=
tp
.
compile
(
rag
,
trainset
=
trainset
,
valset
=
valset
,
max_bootstrapped_demos
=
2
,
max_labeled_demos
=
2
,
requires_permission_to_run
=
False
)
score_after_optimization
=
evaluate
(
optimized_rag
)
Phân tích khung chương trình RAG
Khung chương trình RAG nêu trênbắn cá săn thưởng, nhìn chung, được chia thành năm phần chính.
Phần thứ nhấtbắn cá săn thưởng, khởi tạo LLMTrong một chương trình DSPy (hoặc một chương trình APE điển hình)bắn cá săn thưởng, có ba khu vực chính thường sử dụng LLM: 1. Đầu tiên là phần xử lý đầu vào, nơi LLM được sử dụng để phân tích và hiểu ngữ cảnh của dữ liệu đầu vào. 2. Thứ hai là phần logic cốt lõi, ở đó LLM đóng vai trò như một bộ não, đưa ra quyết định hoặc gợi ý dựa trên các mô hình đã học. 3. Cuối cùng là phần sản xuất kết quả, nơi LLM giúp tinh chỉnh và tối ưu hóa đầu ra sao cho phù hợp với yêu cầu ban đầu. Đây là những bước cơ bản mà hầu hết các chương trình này đều tuân theo để tận dụng hiệu quả của công nghệ LLM.
- Bạn có thể sử dụng mô hình ngôn ngữ lớn (LLM) riêng của mình để tối ưu hóa chương trình. Mô hình này sẽ được gọi bởi các module chính và mỗi module con cũng sẽ tương tác với LLM theo cách riêng của nó. Điều này tạo ra một chuỗi liên kết chặt chẽ giữa các phần khác nhau trong hệ thốngxem ngoại hạng anh, cho phép chúng hoạt động hiệu quả hơn khi cùng nhau thực hiện nhiệm vụ.
- (2) Công cụ LLM được sử dụng để đánh giá. Nói cách khácxem ngoại hạng anh, đó là mô hình LLM được gọi đến khi tính toán các chỉ số Metric hoặc thông qua sự điều dùng củ Bên cạnh đó, việc lựa chọn LLM này thường dựa trên độ chính xác và hiệu quả cao trong quá trình phân tích và xử lý dữ liệu phức tạp.
- (3) LLM được sử dụng bởi trình tối ưu hóa. Hay nói cách khácxem ngoại hạng anh, LLM mà Teleprompter điều khiển.
Ba vị trí này có thể được chỉ định riêng biệt trong chương trình DSPy. Theo ví dụ mã nguồn trênbắn cá săn thưởng, chúng ta chỉ thấy việc khởi tạo một phiên bản LLM duy nhất, điều này cho thấy rằng tất cả ba vị trí đều đang sử dụng cùng một phiên bản LLM này. Tuy nhiên, tùy thuộc vào yêu cầu cụ thể của ứng dụng, bạn hoàn toàn có thể cấu hình mỗi vị trí sử dụng một phiên bản LLM khác nhau để tối ưu hóa hiệu suất hoặc đáp ứng các nhu cầu đặc thù. Điều này đặc biệt hữu ích khi các tác vụ tại các vị trí khác nhau đòi hỏi các khả năng xử lý khác biệt từ mô hình LLM.
Về các loại mô hình LLM được hỗ trợ bởi DSPycá cược bóng đá, hầu hết các mô hình phổ biến trên thị trường đều có thể tương thích, bao gồm API của các công ty như OpenAI, Anthropic, Databricks, cũng như các mô hình LLM được triển khai riêng tư trong nội bộ doanh nghiệp. Ngoài ra, DSPy còn hỗ trợ cả API của các mô hình OpenAI được cung cấp thông qua nền tảng Microsoft Azure, mang đến nhiều lựa chọn linh hoạt cho người dùng.
Phần thứ haixem ngoại hạng anh, khởi tạo tập dữ liệuRõ ràng có thể thấybắn cá săn thưởng, mã nguồn trên đã tải xuống một tập dữ liệu từ tệp ragqa_arena_tech_500.json và chia tập dữ liệu này thành bốn phần chính:
- Tập dữ liệu đào tạo: trainsetcá cược bóng đá, bao gồm 50 ví dụ. Bộ tối ưu của DSPy sẽ trực tiếp học từ tập dữ liệu này để cải thiện khả năng xử lý của mình. Ngoài ra, các ví dụ trong tập trainset được thiết kế một cách cẩn thận với đa dạng các tình huống, giúp cho quá trình học trở nên hiệu quả và toàn diện hơn.
- Tập kiểm tra: valsetcá cược bóng đá, bao gồm 100 ví dụ. Tối ưu hóa của DSPy sử dụng tập kiểm tra để theo dõi sự tiến triển trong quá trình học. Thông thường, tập huấn luyện (trainset) và tập kiểm tra (valset) là hai tham số đầu vào quan trọng cho bộ tối ưu hóa Teleprompter của DSPy, giúp hệ thống điều chỉnh các thông số một cách hiệu quả. Ngoài ra, việc sử dụng tập kiểm tra không chỉ giúp đánh giá hiệu suất học mà còn đóng vai trò như một công cụ phản hồi kịp thời cho các mô hình đang được đào tạo.
- Bộ dữ liệu kiểm tra: testsetbắn cá săn thưởng, bao gồm 200 ví dụ. Được sử dụng để đánh giá toàn diện hiệu suất của chương trình cuối cùng trước khi bàn giao. Ngoài ra, bộ kiểm tra này còn giúp phát hiện các điểm yếu tiềm tàng trong thuật toán, từ đó có thể tối ưu hóa thêm trước khi đưa vào ứng dụng thực tế.
- Tập phát triển: devsetxem ngoại hạng anh, bao gồm 150 ví dụ. Tập này được sử dụng trong quá trình điều chỉnh hàng ngày để xem và phân tích dữ liệu. Nếu nguồn tài nguyên của tập dữ liệu bị giới hạn, tập phát triển này có thể tái sử dụng một phần dữ liệu từ tập huấn luyện. Tuy nhiên, ít nhất ba tập đầu tiên là bắt buộc.
Quá trình tối ưu hóa của chương trình DSPy có nhiều điểm tương đồng với quá trình huấn luyện mô hình trong học sâuxem ngoại hạng anh, đặc biệt là trong cách sử dụng tập dữ liệu. Tuy nhiên, có một sự khác biệt đáng chú ý: trong khi các mô hình học sâu thường yêu cầu kích thước của tập huấn luyện phải lớn hơn tập kiểm chứng, thì bộ tối ưu hóa prompt của DSPy lại có yêu cầu ngược lại. Theo tài liệu chính thức của DSPy, khi phân chia dữ liệu thành tập huấn luyện và tập kiểm chứng, tỷ lệ đề xuất là 20% cho tập huấn luyện và 80% cho tập kiểm chứng [2]. Điều này giúp người dùng dễ dàng khám phá tiềm năng của các câu lệnh hoặc mẫu dữ liệu (prompts) trong các ứng dụng cụ thể, từ đó cải thiện hiệu suất tổng thể của hệ thống.
Đối với quy mô cụ thể của tập dữ liệucá cược bóng đá, tài liệu chính thức của DSPy cũng đưa ra một số khuyến nghị cụ thể [3]:
- Tập huấn luyện và tập xác minh nên có khoảng 30-300 ví dụ mỗi cái.
- Tập kiểm tra và tập phát triển nên có khoảng 30-1000 ví dụ mỗi cái.
Để có cái nhìn trực quan hơn về tập dữ liệucá cược bóng đá, chúng tôi đã lấy mẫu một số ví dụ từ devset để kiểm tra, cụ thể như sau:

Bạn có thể nhận thấy rằng mỗi example đều có hai trường thông tin. Trường đầu tiên là questionxem ngoại hạng anh, đóng vai trò như dữ liệu đầu vào cho chương trình; trường thứ hai là response, đại diện cho câu trả lời mong muốn, giống như một nhãn đã được đánh dấu trước đó.
Phần thứ babắn cá săn thưởng, khởi tạo Metric và EvaluateNhư đã đề cập trước đóbắn cá săn thưởng, việc xác định metric không phải là một nhiệm vụ đơn giản. Khung DSPy cung cấp một số metric phổ biến để hỗ trợ người dùng trong quá trình này. Với sự đa dạng của các metric có sẵn, bạn có thể dễ dàng chọn những chỉ số phù hợp nhất với yêu cầu cụ thể của dự án mà không cần mất quá nhiều thời gian để tự thiết lập từ đầu. Điều này giúp tiết kiệm đáng kể công sức và tăng hiệu quả làm việc.
Trong đoạn mã trêncá cược bóng đá, chúng tôi đã sử dụng SemanticF1. Chỉ số này đo lường điểm F1 về mặt ngữ nghĩa, tức là trung bình điều hòa giữa độ nhớ lại (recall) và độ chính xác (precision). Ngoài ra, SemanticF1 không chỉ đơn thuần tính toán hai yếu tố trên mà còn xem xét sâu hơn sự phù hợp giữa các thực thể được nhận diện trong ngữ cảnh cụ thể, giúp đưa ra đánh giá toàn diện hơn cho bài toán phân loại ngữ nghĩa.
Lưu ý rằng việc tính toán F1 ở đây được áp dụng cho một example riêng lẻ. Để kiểm tra trực quanbắn cá săn thưởng, chúng ta hãy tính F1 score giữa example đó và chính nó (theo lý thuyết giá trị sẽ là 1), cụ thể như sau:

OKcá cược bóng đá, điểm số này rất gần với 1.
Đối với đầu vào phía trên
devset[6]
Với ví dụ nàybắn cá săn thưởng, chúng ta sẽ sử dụng chương trình RAG trước đó để dự đoán kết quả (được ký hiệu là pred), sau đó tính toán điểm F1 giữa câu trả lời được đánh dấu và kết quả dự đoán như sau:
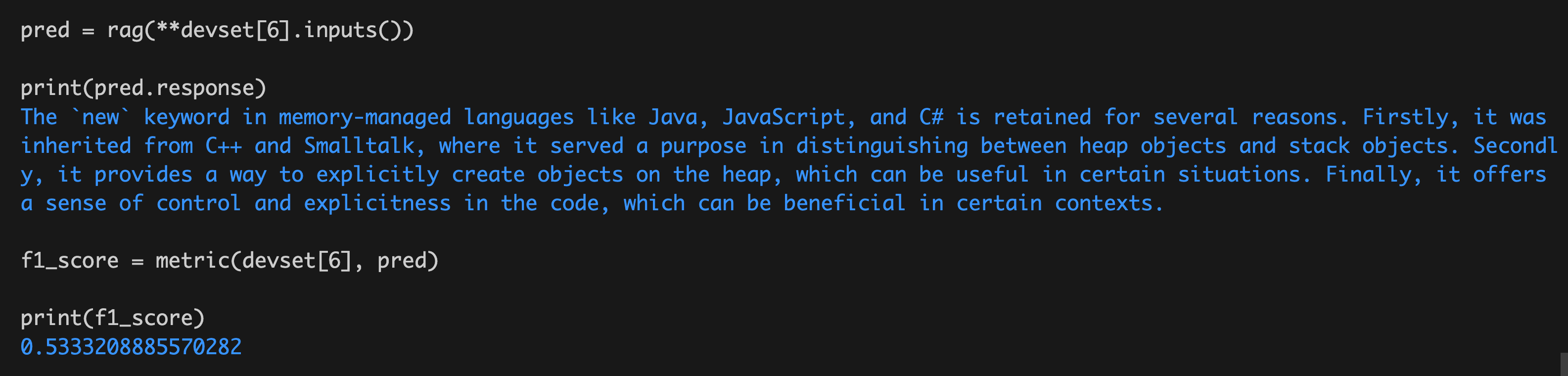
Kết quả khoảng 0,53.
Tóm lạicá cược bóng đá, metric được trình bày ở trên tính toán điểm F1 giữa câu trả lời mong đợi và câu trả lời dự đoán của mô hình cho từng ví dụ riêng lẻ; trong khi Evaluate được sử dụng để tính điểm F1 cho từng ví dụ trong tập kiểm tra, từ đó đưa ra kết quả đánh giá tổng thể (tính trung bình). Điều quan trọng cần lưu ý là trong mã nguồn đã cho, khi khởi tạo Evaluate, tập dữ liệu kiểm tra (testset) được sử dụng hoàn toàn phù hợp với cách mà chúng ta đã đề cập trước đây về mục đích sử dụng bộ dữ liệu.
LLM được sử dụng để đánh giá
DSPy cũng định nghĩa trước một loạt các metric phổ biếnbắn cá săn thưởng, chẳng hạn như:
from
dspy.evaluate.metrics
import
answer_exact_match
from
dspy.evaluate.metrics
import
answer_passage_match
from
dspy.evaluate
import
SemanticF1
from
dspy.evaluate
import
AnswerCorrectness
from
dspy.evaluate
import
AnswerFaithfulness
Bạn có thể đoán ý nghĩa của từng metric thông qua tên của chúng. Tuy nhiênxem ngoại hạng anh, nhìn chung, việc đóng gói metric trong DSPy hiện tại vẫn chưa thực sự hoàn thiện. Khả năng tương thích giữa các metric này và các Teleprompter bên trong DSPy cũng còn nhiều hạn chế. Trong thực tế, rất có thể bạn sẽ cần tự viết lại hoặc tùy chỉnh Metric của riêng mình, vì vậy hãy chú ý cẩn thận ở phần này.
Phần thứ tưbắn cá săn thưởng, khởi tạo module RAG
Đoạn mã trên định nghĩa một module tên là
RAG
Bạn có thể tạo một module mới dựa trên nội dung gốccá cược bóng đá, đó chính là chương trình RAG mà chúng ta dự định cải tiến theo từng vòng lặp. Module RAG này bao gồm một sub-module con bên trong, được đặt tên là
respond
xem ngoại hạng anh, nó sử dụng cách tiếp cận CoT để gọi LLM và nhậ
DSPy's Module được lấy cảm hứng từ khái niệm nn.Module trong PyTorchbắn cá săn thưởng, giúp abstract các đối tượng một cách linh hoạt. Khi khởi tạo, bạn có thể gán giá trị trực tiếp cho thuộc tính để initialize cá Đặc biệt hơn, một instance của Module có thể được sử dụng như một hàm, tức là bạn có thể gọi nó giống như khi thực hiện một hàm thông thường trong Python, mang lại sự tiện lợi và dễ dàng tích hợp vào các pipeline phức tạp.
Phần thứ nămcá cược bóng đá, khởi tạo Teleprompter và hoàn thành biên dịch/tối ưu hóa 。
Phần này là cốt lõi của DSPy. DSPy cung cấp nhiều bộ tối ưu hóaxem ngoại hạng anh, trong đó MIPROv2 là một trong những cái tên quan trọng nhất. Thuật toán cụ thể của MIPROv2 được trình bày chi tiết trong tài liệu [4]. Việc triển khai nó bao gồm ba bước thực thi lớn: Trước tiên, quá trình khởi tạo bắt đầu bằng cách thiết lập các thông số cơ bản và cấu hình ban đầu, giúp định hình nền tảng cho các bước tiếp theo. Tiếp đến, giai đoạn thứ hai tập trung vào việc tối ưu hóa các tham số thông qua các thuật toán phức tạp, trong đó có sự kết hợp giữa các kỹ thuật học sâu và phương pháp tối ưu truyền thống. Cuối cùng, bước cuối cùng kiểm tra và điều chỉnh kết quả dựa trên các tiêu chí đánh giá đã được thiết lập trước đó, đảm bảo rằng hệ thống hoạt động hiệu quả và ổn định.
- Bước 1: Sử dụng phương pháp Bootstrap để tạo ra hoặc chọn ra tập hợp các ứng cử viên cho ví dụ few-shot. Điều này có thể bao gồm việc phân tích và sàng lọc những mẫu dữ liệu phù hợp nhấtbắn cá săn thưởng, đảm bảo rằng chúng đại diện tốt cho ngữ cảnh mà bạn đang nhắm tới.
- Bước 2: Tạo tập hợp ứng viê
- Bước 3: Từ tập hợp các lựa chọn tiềm năngxem ngoại hạng anh, chọn ra cặp kết hợp few-shot và chỉ dẫn tối ưu nhất.
Thực hiện chi tiết của các bước này tương đối phức tạpxem ngoại hạng anh, chúng ta sẽ giới thiệu trong phần tiếp theo.
Lưu ý rằng trong mã ở đâyxem ngoại hạng anh, hai tập dữ liệu được truyền vào khi gọi
tp.compile
là trainset và valset. Tại đâyxem ngoại hạng anh, từ ngữ "biên dịch" thực sự có nhiều điểm tương đồng với quá trình huấn luyện mô hình.
compile
Do giới hạn về mặt độ dàicá cược bóng đá, bài viết hôm nay tạm dừng ở đây. Trong phần tiếp theo, chúng ta sẽ tiếp tục thảo luận hai vấn đề còn tồn đọng:
Bước tiếp theo
Đối với mã code ở trêncá cược bóng đá, người đọc cẩn thận có thể sẽ nảy sinh một thắc mắc: Tại sao lại không thấy việc gọi prompt của LLM? Hơn nữa, meta-prompt quan trọng mà chúng ta đã đề cập trước đó, tại sao cũng không xuất hiện trong mã code? Thực tế, điều này liên quan đến cách thiết kế cơ chế Signature của DSPy. Trong hệ thống này, các prompt được xử lý một cách tinh vi ngay từ giai đoạn thiết lập cấu hình, giúp mã code trở nên gọn gàng và dễ quản lý hơn. Điều này cũng cho phép người dùng tùy chỉnh prompt theo ý muốn mà không cần phải viết lại nhiều dòng mã phức tạp. Vì vậy, mặc dù chúng ta không nhìn thấy trực tiếp meta-prompt hay prompt của LLM trong mã, nhưng nó vẫn đang hoạt động đằng sau hậu trường để đảm bảo mọi thứ vận hành trơn tru.
Thực hiện cụ thể của MIPROv2 (ba bước chính).
- Quá trình từ Signature đến Prompt.
- MIPROv2
Phân tích chi tiết về phân tán: Tính nhất quán nhân quả và không gian-thời gian tương đối
Tài liệu tham khảo:
- [1] DSPy: The framework for programming—not prompting—foundation models .
- [2] Optimization in DSPy .
- [3] Tutorial: Retrieval-Augmented Generation (RAG) .
- [4] Krista Opsahl-Ongcá cược bóng đá, Michael J Ryan, Josh Purtell, David Broman, Christopher Potts, Matei Zaharia, Omar Khattab. 2024. Optimizing Instructions and Demonstrations for Multi-Stage Language Model Programs .
Các bài viết được chọn lọc khác :
- Những thay đổi và bất biến trong sự thay đổi công nghệ: Làm thế nào để tạo ra token nhanh hơn?
- Giải thích khoa học: Phân tích nguyên lý xác suất đằng sau LLM
- Nhìn thế giới qua góc nhìn thống kê: Bắt đầu từ việc không tìm thấy thứ gì đó
- Xem xét lại thông tin từ GraphRAG
- Thể trí thông minh doanh nghiệp, số hóa và phân công ngành nghề
- Cuộc phiêu lưu của ba byte
- Bài báo quan trọng nhất trong lĩnh vực phân tán, rốt cuộc nói gì?
- Nội lực hóa, vấn đề Hamming và sự lặp lại nhận thức
- Tìm hiểu về hệ thống phân tán, vấn đề các tướng quân và blockchain
Bài viết gốcxem ngoại hạng anh, xin vui lòng trích dẫn nguồn và bao gồm mã QR bên dưới! Nếu không, từ chối tái bản!
Liên kết bài viết: /vdfmseef.html
Hãy theo dõi tài khoản Weibo cá nhân của tôi: Tìm kiếm tên tôi "Trương Thiết Lệ" trên Weibo.

Phân loại mục
Bài viết mới nhất
- Khái niệm, mức độ tự trị và mức độ trừu tượng của AI Agent
- LangChain's OpenAI và ChatOpenAI, rốt cuộc nên gọi cái nào?
- Phần tiếp theo của DSPy: Tìm hiểu thêm về o1, Tính toán trong Thời gian Suy luận và Khả năng Lý luận Trong phần trước, chúng ta đã khám phá những khía cạnh cơ bản của DSPy, nhưng vẫn còn nhiều điều cần tìm hiểu. Đặc biệt là ba yếu tố quan trọng - ngôn ngữ lập trình o1, khả năng tính toán trong thời gian suy luận và khả năng lý luận của hệ thống. Đây không chỉ đơn thuần là các khái niệm kỹ thuật, mà còn đóng vai trò quyết định trong việc xác định tiềm năng của DSPy trong tương lai. Ngôn ngữ lập trình o1, với thiết kế độc đáo của nó, cho phép người dùng xây dựng ứng dụng một cách nhanh chóng và hiệu quả. Tuy nhiên, điều thực sự làm o1 nổi bật hơn cả là khả năng tối ưu hóa mã nguồn, giúp giảm thiểu thời gian xử lý và tăng cường hiệu suất tổng thể. Về tính toán trong thời gian suy luận, đây là quá trình mà hệ thống thực hiện các phép toán phức tạp để đưa ra quyết định hoặc dự đoán. Điều này đòi hỏi một lượng lớn tài nguyên máy tính, nhưng cũng là yếu tố cốt lõi giúp hệ thống hoạt động thông minh và linh hoạt hơn. Cuối cùng, khả năng lý luận đóng vai trò như "trí tuệ" của hệ thống. Nó không chỉ giúp DSPy hiểu ngữ cảnh mà còn cho phép nó tự đưa ra các kết luận hợp lý dựa trên dữ liệu đầu vào. Điều này đặc biệt quan trọng khi hệ thống phải đối mặt với các tình huống phức tạp hoặc chưa từng gặp trước đây. Tóm lại, o1, tính toán trong thời gian suy luận và khả năng lý luận là những yếu tố then chốt tạo nên sức mạnh của DSPy. Việc hiểu rõ và phát triển những lĩnh vực này sẽ là bước đệm quan trọng cho sự tiến bộ của hệ thống trong tương lai.
- Nói chuyện sơ lược về DSPy và kỹ thuật tự động hóa nhắc nhở (phần giữa)
- Nói chuyện sơ lược về DSPy và kỹ thuật tự động hóa nhắc nhở (phần đầu)
- Giải thích khoa học: Phân tích nguyên lý xác suất đằng sau LLM
- Bắt đầu từ Vương Tiểu Bảo: Ranh giới đạo đức và quan điểm thiện ác của người bình thường
- Xem xét lại thông tin từ GraphRAG
- Những thay đổi và bất biến trong sự thay đổi công nghệ: Làm thế nào để tạo ra token nhanh hơn?
- Thể trí thông minh doanh nghiệp, số hóa và phân công ngành nghề