Tinh thần khoa học và thí nghiệm A/B trên internet
2019-08-18
Chúng ta hãy kể trước hai câu chuyện nhỏ thực tế đã xảy ra trong lịch sử.
Câu chuyện đầu tiên là về bệnh vàng da.
Vi-rút vàngcá cược bóng đá, một căn bệnh truyền nhiễm nghiêm trọng, từng bùng phát dữ dội tại Philadelphia vào năm 1793. Khi đó, thành phố này có một nhân vật nổi tiếng tên là Benjamin Rush [1]. Rush không chỉ là người ký bản Tuyên ngôn Độc lập mà còn là một trong những nhà sáng lập của nước Mỹ. Ngoài ra, ông còn là một giáo sư tài ba và bác sĩ phẫu thuật xuất sắc. Trong thời gian dịch bệnh vàng da bùng phát ở Philadelphia, Rush tin rằng phương pháp rút máu có thể chữa khỏi căn bệnh này. Vì vậy, ông đã sử dụng dao mổ hoặc đặt lươn máu lên cơ thể bệnh nhân để thực hiện quá trình rút máu. Khi chính Rush mắc phải căn bệnh này, ông cũng áp dụng cách điều trị tương tự lên bản thân mình. Dù nỗ lực của Rush được cho là xuất phát từ mong muốn cứu người, nhưng phương pháp điều trị của ông lại gây nhiều tranh cãi. Nhiều người đồng tình, trong khi không ít người khác cho rằng cách làm này chỉ làm trầm trọng thêm tình hình. Dù kết quả cuối cùng ra sao, câu chuyện về Rush vẫn là một phần quan trọng trong lịch sử y học và sự phát triển củ
Câu chuyện thứ hai là về bệ
Bệnh scorbut từng là một mối đe dọa nghiêm trọng đối với sức khỏe con người trong lịch sửcá cược bóng đá, đặc biệt là đối với thủy thủ đoàn trên những chuyến hành trình dài ra biển khơi. Đến thế kỷ 18, một vị thuyền trưởng người Anh nhận thấy rằng các thủy thủ phục vụ trên các tàu chiến của các quốc gia ven Địa Trung Hải không hề mắc bệnh này. Điều khiến ông chú ý là thực đơn của họ bao gồm các loại trái cây họ cam quýt. Với sự tò mò và mong muốn tìm hiểu nguyên nhân, vị thuyền trưởng quyết định chia thủy thủ đoàn của mình thành hai nhóm: một nhóm được bổ sung nước ép từ quả chanh xanh vào chế độ ăn hàng ngày, còn nhóm kia vẫn duy trì thực đơn cũ. Sau một thời gian theo dõi, kết quả thật bất ngờ. Nhóm được bổ sung chanh xanh hoàn toàn không bị mắc scorbut, trong khi nhóm còn lại xuất hiện nhiều trường hợp mắc bệnh. Từ đó, việc ăn uống đều đặn các loại quả họ cam quýt trở thành một quy định bắt buộc đối với các thủy thủ Anh. Sự phổ biến của phương pháp này dần lan rộng, đến mức từ "limey" - ám chỉ người Anh - xuất hiện trong tiếng Anh Mỹ. Từ này sau này được dịch sang tiếng Trung Quốc với nghĩa gần giống như "người Anh". Điều thú vị là hành động đơn giản của vị thuyền trưởng này không chỉ cứu sống nhiều người mà còn góp phần làm thay đổi cách nhìn nhận về dinh dưỡng trong giới y học. Ngày nay, chúng ta đã hiểu rõ vai trò quan trọng của vitamin C trong việc ngăn ngừa scorbut, nhưng câu chuyện về vị thuyền trưởng này vẫn luôn là một ví dụ điển hình cho sự kết nối giữa khoa học và cuộc sống thường nhật.
Bây giờ hãy so sánh xem hai câu chuyện này có gì khác biệt.
Trong câu chuyện đầu tiêncá cược bóng đá, Benjamin Rush kiên định rằng phương pháp chữa bệnh bằng việc rút máu của mình có thể trị khỏi bệnh vàng da. Thực tế, ông ta thật sự đã "cứu" được một số bệnh nhân. Tất nhiên, cũng có những trường hợp bệnh nhân qua đời. Giải thích cho điều này trở nên phức tạp: nếu bệnh nhân cải thiện, thì đó sẽ là minh chứng cho hiệu quả của phương pháp rút máu; còn nếu bệnh nhân chết, Rush lại biện minh rằng tình trạng bệnh quá nặng và không có cách nào cứu vãn được nữa. Về sau, các nhà phê bình chỉ ra rằng chính phương pháp của ông thậm chí còn nguy hiểm hơn cả căn bệnh ấy. Những lời chỉ trích này xuất phát từ thực tế rằng, thay vì giảm bớt nguy cơ tử vong, phương pháp của Rush đôi khi khiến bệnh nhân yếu đi nhanh chóng, khiến họ không đủ sức chống chọi với căn bệnh nguy hiểm đang hành hạ cơ thể. Sự lạc quan mù quáng của Rush đã dẫn đến hậu quả nghiêm trọng, làm tăng thêm áp lực đối với hệ thống y tế vốn đã căng thẳng trong thời kỳ dịch bệnh bùng phát.
Trong câu chuyện thứ haicá cược bóng đá, thuyền trưởng chia nhóm thủy thủ thành hai phần và tiến hành Thí nghiệm đối chứng Thí nghiệm kiểm soát hiện đại đã chứng minh rằng kết luận mà vị thuyền trưởng rút ra từ các thí nghiệm đối chứng thực sự là chính xác. Nguyên nhân gây bệnh scorbut (còn gọi là bệnh huyết) là do cơ thể thiếu hụt vitamin Ccá cược bóng đá, trong khi các loại trái cây họ cam quýt lại chứa một lượng lớn vitamin C, giúp ngăn ngừa và cải thiện tình trạng này. Ngoài ra, việc bổ sung thêm rau xanh và thực phẩm giàu dưỡng chất cũng có thể góp phần tăng cường sức khỏe tổng thể, đặc biệt là trong những chuyến hành trình dài trên biển.
Trong hai câu chuyện nàybắn cá săn thưởng, các bên liên quan đều cố gắng tìm kiếm mối quan hệ Nhân quả Benjamin Rush tin rằng có mối liên hệ nhân quả giữa việc pha máu và điều trị bệnh vàng da; trong khi đóbắn cá săn thưởng, người thuyền trưởng trong câu chuyện thứ hai lại khám phá ra mối liên hệ nhân quả giữa việc ăn cam quýt và ngăn ngừa bệ Vậy tại sao Rush lại không tìm ra mối liên hệ đúng đắn trong khi thuyền trưởng Anh lại làm được? Điều quan trọng ở đây chính là thực nghiệm đối chứng. Rush đã dựa vào cảm tính và kinh nghiệm cá nhân mà không có đủ bằng chứng khoa học vững chắc để kiểm chứng. Trong khi đó, người thuyền trưởng ấy đã nhận ra rằng các thủy thủ của mình thường bị scorbut khi họ không được tiếp cận với thực phẩm tươi, đặc biệt là rau củ và trái cây già Chính nhờ việc so sánh những thủy thủ được cung cấp cam quýt với những người không được cung cấp, ông đã phát hiện ra rằng cam quýt có khả năng phòng ngừa bệnh này một cách hiệu quả. Thực nghiệm đối chứng đóng vai trò then chốt trong việc xác định mối quan hệ nhân quả. Nếu không có sự so sánh rõ ràng giữa nhóm đối tượng thử nghiệm và nhóm đối chứng, thì việc xác định nguyên nhân thực sự trở nên vô cùng khó khăn. Vì vậy, thực nghiệm đối chứng là công cụ không thể thiếu trong việc tìm hiểu thế giới xung quanh chúng ta.
Tiếp tục khai thác vấn đềcá cược bóng đá, tại sao sử dụng thí nghiệm đối chứng có thể giúp chúng ta tìm ra mối quan hệ nhân quả thực sự? Về cơ bản, đây là một câu hỏi triết học, liên quan đến bản chất cốt lõi của điều khiến khoa học trở thành khoa học. Trước tiên, chúng ta sẽ đi sâu vào xem mối quan hệ nhân quả thực sự là gì và cách nó phản ánh bản chất của khoa học; sau đó, chúng ta sẽ quay về thực tế, cùng thảo luận với mọi người về các kỹ thuật khác nhau để thực hiện thí nghiệm đối chứng trong lĩnh vự Khi nghiên cứu về mối quan hệ nhân quả, điều quan trọng không chỉ là việc xác định rằng một yếu tố ảnh hưởng đến một yếu tố khác mà còn phải đảm bảo rằng sự thay đổi trong kết quả không phải do các yếu tố khác gây ra. Thí nghiệm đối chứng đóng vai trò như một công cụ mạnh mẽ để kiểm soát những biến số không mong muốn, từ đó giúp chúng ta đưa ra kết luận chính xác hơn về nguyên nhân thực sự đằng sau một hiện tượng nào đó. Đây chính là lý do tại sao phương pháp này được xem là nền tảng của phương pháp luận khoa học hiện đại. Trong thế giới thực, đặc biệt là trong lĩnh vực kinh doanh internet, việc thiết kế và triển khai thí nghiệm đối chứng đòi hỏi nhiều kỹ năng và hiểu biết sâu sắc. Đầu tiên, bạn cần xác định rõ mục tiêu của mình – điều bạn muốn kiểm tra là gì và liệu có đủ dữ liệu để hỗ trợ quá trình phân tích hay không. Tiếp theo, bạn cần xây dựng một nhóm đối chứng phù hợp, đảm bảo rằng cả hai nhóm (đối chứng và thử nghiệm) đều có đặc điểm tương tự nhau để loại trừ các yếu tố nhiễu. Cuối cùng, bạn cần phân tích kết quả một cách cẩn thận, sử dụng các công cụ thống kê để đánh giá mức độ đáng tin cậy của kết luận. Việc hiểu rõ bản chất của mối quan hệ nhân quả và khả năng áp dụng nó vào thực tiễn không chỉ giúp cải thiện hiệu suất hoạt động của doanh nghiệp mà còn nâng cao khả năng cạnh tranh trên thị trường. Hy vọng qua buổi thảo luận hôm nay, chúng ta có thể cùng nhau khám phá thêm nhiều khía cạnh thú vị liên quan đến chủ đề này.
Bẫy quy luật nhân quả
Mỗi khi chúng ta đưa ra một kết luận về tính nhân quả123win+club, hãy thật cẩn trọng. Ví dụ như khi thấy một quả táo rơi xuống đất, làm sao chúng ta có thể khẳng định rằng lực hấp dẫn là nguyên nhân duy nhất khiến nó rơi? Có phải không có lý do khác nào có thể giải thích hiện tượng này? Hãy nghĩ xem, còn rất nhiều yếu tố khác mà chúng ta có thể cân nhắc: thời tiết chẳng hạn, vị trí địa lý, giống táo mà nó thuộc loại nào... Tại sao những yếu tố đó lại không thể là nguyên nhân cho việc táo rơi xuống đất? Tại sao chúng ta không thể kết luận rằng vì hôm nay trời nắng đẹp nên táo mới rơi xuống đất, còn ngày mai khi trời mưa, táo sẽ tự nhiên bay lên trời? Và tại sao chúng ta không thể nói rằng táo rơi xuống đất vì nó được trồng ở Hà Bắc, còn đối với táo trồng ở Hồ Nam thì hoàn toàn có thể khác? Thật sự, trong thế giới của khoa học và triết học, mọi thứ không bao giờ đơn giản như chúng ta tưởng tượng. Mỗi hiện tượng đều có thể có hàng tá các yếu tố tác động cùng lúc, và việc xác định nguyên nhân thực sự đòi hỏi sự cẩn trọng và logic chặt chẽ. Nếu không, chúng ta có nguy cơ rơi vào cái bẫy của tư duy đơn giản hóa, biến mọi thứ trở nên dễ hiểu hơn so với thực tế vốn phức tạp. Và điều đó cũng nhắc nhở chúng ta rằng, sự thật đôi khi nằm sâu bên dưới lớp vỏ của những gì mắt thường có thể quan sát.
lực hấp dẫn vạn vật
Ví dụ về quả táo rơi từ trên cây cho thấy việc tìm ra mối quan hệ nhân quả thực sự không hề đơn giản. Trước thời đại của Newtoncá cược bóng đá, hàng trăm, thậm chí hàng nghìn năm, con người đã quen thuộc với hiện tượng này nhưng vẫn chưa thể hiểu được lý do thật sự đằng sau. Nếu nhầm lẫn giữa nguyên nhân và kết quả, chúng ta có thể đưa ra những kết luận hết sức phi lý và vô lý. Điều này nhấn mạnh tầm quan trọng của việc suy nghĩ cẩn thận và nghiên cứu kỹ lưỡng trước khi đi đến bất kỳ kết luận nào.
Ông đã phát triển triết học kinh nghiệm của Locke và Berkeley đến tận cùng logic123win+club, và vì sự nhất quán của nó, nó trở thành một thứ mà khó có thể tin được.
Trong tiểu thuyết *Tam Thể*cá cược bóng đá, có đề cập đến một giả thuyết được gọi là giả thuyết chủ trang trại, điều này khá tương đồng với quan điểm của. Giả thuyết này được diễn giải như sau: Chúng ta thường tin rằng mình đang sống trong một thế giới tự nhiên, nơi các quy luật vật lý và thực tại vận hành theo một trình tự nhất định. Tuy nhiên, giả thuyết chủ trang trại lại cho rằng toàn bộ vũ trụ mà chúng ta nhận thức chỉ đơn thuần là một trang trại lớn, nơi một sinh vật nào đó cao cấp hơn đang nghiên cứu chúng, giống như cách con người nuôi dưỡng và quan sát côn trùng hay động vật trong một môi trường khép kín. Có thể chúng ta đang bị điều khiển bởi một lực lượng bên ngoài mà không hề hay biết, và mọi hiện tượng tự nhiên mà chúng ta tưởng là logic thực ra chỉ là sản phẩm của sự sắp đặt từ chủ trang trại này. Giả thuyết này không chỉ đặt ra câu hỏi về bản chất của thực tại mà còn làm chúng ta suy ngẫm sâu sắc về vị trí của con người trong vũ trụ bao la này.
Mỗi sáng thứ Năm cuối cùng của tháng Mười mộtbắn cá săn thưởng, thức ăn sẽ đến.
mười một giờ sáng
Chúng ta nhanh chóng nhận ra rằng123win+club, nếu theo cách suy nghĩ này mà hoàn toàn không thừa nhận sự tồn tại của luật nhân quả trong thế giới này, thì việc nghiên cứu khoa học sẽ trở nên bất khả thi. Để nghiên cứu khoa học có thể tiếp tục tiến triển, chúng ta cần công nhận rằng luật nhân quả là một quy luật phổ quát, vì hầu hết các định luật khoa học đều được rút ra từ những quan sát và tổng kết về mối liên hệ nhân quả. Lý do chúng ta nên thừa nhận và tôn trọng khoa học chính là vì tính hữu ích của nó, đã từng bước thay đổi sâu sắc cuộc sống của con người trong vài thế kỷ qua. Chúng ta cần chuyển sang quan điểm thực dụng, nếu không sẽ dễ sa vào những tranh luận vô nghĩa và mịt mờ. Tóm lại, chúng ta nên kịp thời từ bỏ quan điểm cực đoan của Hume, quay trở lại niềm tin vào sự tồn tại của luật nhân quả. Hơn nữa, khi không thừa nhận luật nhân quả, chúng ta cũng khó lòng giải thích được những hiện tượng phức tạp trong tự nhiên hay những phát minh mang tính cách mạng của khoa học. Chính sự hiểu biết về luật nhân quả đã giúp con người xây dựng nên những nền tảng vững chắc cho sự phát triển của xã hội loài người. Vì vậy, việc tin tưởng vào luật nhân quả không chỉ là điều cần thiết trong nghiên cứu khoa học mà còn là yếu tố cơ bản để duy trì trật tự trong thế giới tự nhiên và xã hội.
thí nghiệm đối chứng
Đối chiếu thí nghiệm là gì? Đơn giản mà nói123win+club, đối chiếu thí nghiệm chính là việc chia ngẫu nhiên đối tượng hoặc nhóm người tham gia thí nghiệm thành hai nhóm: một nhóm thí nghiệm (experiment group) và một nhóm đối chứng (control group). Với nhóm thí nghiệm, các nhà nghiên cứu sẽ can thiệp vào một yếu tố điều khiển (còn gọi là biến độc lập), tức là thực hiện thí nghiệm theo cách nào đó. Còn nhóm đối chứng chỉ đóng vai trò so sánh, không có sự thay đổi nào xảy ra với tình trạng ban đầu của nó. Hãy lấy ví dụ về câu chuyện bệnh scorbut (bệnh hoại huyết) được đề cập ở phần mở đầu: thuyền trưởng người Anh đã tiến hành một thí nghiệm đối chiếu. Ông đã ngẫu nhiên chia các thủy thủ thành hai nhóm: nhóm được bổ sung nước ép chanh trong chế độ ăn uống hàng ngày là nhóm thí nghiệm, còn nhóm khác tiếp tục duy trì chế độ ăn như cũ là nhóm đối chứng. Kết quả cuối cùng cho thấy tỷ lệ mắc bệnh scorbut ở nhóm thí nghiệm giảm đáng kể. Nguyên nhân dẫn đến kết quả này, cụ thể là yếu tố làm khác biệt giữa hai nhóm – nước ép chanh. Từ đó, thuyền trưởng rút ra kết luận rằng nước ép chanh có khả năng ngăn ngừa bệ Từ đó, khái niệm đối chiếu thí nghiệm đã trở nên vô cùng quan trọng trong nghiên cứu khoa học, giúp xác định rõ ràng mối liên hệ nhân quả giữa các yếu tố khác nhau trong điều kiện kiểm soát chặt chẽ. Nó không chỉ mang lại lợi ích trong y học mà còn ứng dụng rộng rãi trong nhiều lĩnh vực khác như nông nghiệp, kinh tế hay tâm lý học.
Chúng ta hãy xem thêm một ví dụ về thí nghiệm đối chứng.
Trong cuốn sách *Những Điều Triết Gia Đã Làm*123win+club, có đề cập đến một trường hợp thú vị. Có người đã nghiên cứu mối liên hệ giữa trọng lượng cơ thể và số lượng bạn bè của sinh viên đại học, và họ nhận thấy rằng những người càng nặng cân lại càng có nhiều bạn hơn. Từ đó, họ kết luận rằng việc thân hình đầy đặn chính là nguyên nhân khiến họ được nhiều người yêu mến. Tuy nhiên, bài toán này cũng có thể được xem như một thí nghiệm đối chứng: chúng ta lấy hai nhóm sinh viên, một nhóm có chỉ số khối cơ thể vượt ngưỡng (nhóm thử nghiệm), và nhóm kia có chỉ số bình thường (nhóm đối chứng). Sau khi so sánh số lượng bạn bè của cả hai nhóm, chúng ta nhận ra rằng sinh viên trong nhóm thử nghiệm có nhiều bạn hơn. Từ đây, chúng ta phân tích rằng "số lượng bạn bè" là kết quả, còn "nguyên nhân" của nó nằm ở yếu tố khác biệt giữa hai nhóm – cụ thể là thân hình đầy đặn. Mặc dù kết luận này có vẻ hấp dẫn, nhưng cần phải lưu ý rằng các yếu tố khác có thể ảnh hưởng đến số lượng bạn bè của mỗi cá nhân. Ví dụ, có thể những người nặng cân thường vui tính hoặc dễ tạo thiện cảm hơn, điều này khiến họ thu hút nhiều mối quan hệ hơn. Hoặc cũng có thể họ gặp gỡ nhiều người qua các hoạt động xã hội vì thói quen ăn uống và sinh hoạt tập thể. Điều này nhắc nhở chúng ta rằng không nên vội vàng kết luận chỉ dựa trên một mối liên hệ đơn giản giữa hai yếu tố.
khả năng thích tham gia các buổi liên hoan
Trong thống kêbắn cá săn thưởng, có một kết luận kinh điển rằng mối liên quan không đồng nghĩa với nguyên nhân. Khi tiến hành phân tích dữ liệu, chúng ta thường dễ dàng nhận thấy mối liên hệ giữa hai biến số, chẳng hạn như khi một biến số tăng lên thì biến số kia cũng tăng hoặc khi một biến số tăng thì biến số còn lại giảm. Tuy nhiên, việc hai biến số có mối liên hệ không có nghĩa là chúng có mối quan hệ nhân quả. Chúng ta tuyệt đối không được vội vàng rút ra kết luận chỉ dựa trên sự tương quan này. Thực tế, đôi khi mối liên hệ giữa hai biến số chỉ là ngẫu nhiên, và cần phải có thêm các nghiên cứu sâu hơn để xác định liệu có tồn tại mối liên hệ nhân quả hay không.
bốc thăm ngẫu nhiên
Nói tóm lại123win+club, tất cả những gì đã đề cập đều nhằm nhắc nhở chúng ta rằng khi thiết kế thí nghiệm để khám phá hoặc kiểm chứng quy luật nhân quả, cần phải hết sức cẩn trọng. Dù là các bẫy liên quan thường gặp trong chính các thí nghiệm khoa học hay sự thiên vị trong lựa chọn, hay thậm chí là những thách thức cơ bản từ góc độ triết học đối với quy luật nhân quả, tất cả đều cho thấy việc phân tích mối quan hệ nhân quả giữa các sự vật là một vấn đề đầy thử thách. Và chính vì sự "cẩn trọng" này mà khoa học đã tỏa sáng rực rỡ trong suốt quá trình phát triển lịch sử hiện đại và cận đại.
Thí nghiệm A/B trong kinh doanh internet
Các sản phẩm trên internet thường được phát triển dần dầnbắn cá săn thưởng, từng bước hoàn thiện theo thời gian, và thường có nhiều lựa chọn khác nhau. Điều này tự nhiên dẫn đến một câu hỏi lớn: Ở mỗi bước đi, sản phẩm nên hướng theo hướng nào để tối ưu hóa sự phát triển của doanh nghiệp? Trong quá trình phát triển và vận hành các dịch vụ internet, chúng ta thường phải đối mặt với những vấn đề như vậy và đưa ra quyết định. Ví dụ, khi quyết định thay đổi giao diện trang chủ của sản phẩm, có thể có nhiều phương án khác nhau. Vậy, phương án nào là tốt nhất? Hay như việc nâng cấp thuật toán gợi ý, liệu nó có đảm bảo cải thiện các chỉ số dữ liệu? Thêm vào đó, trong quá trình thương mại hóa, khi muốn đặt quảng cáo vào sản phẩm, làm thế nào để tối đa hóa lợi nhuận mà không ảnh hưởng quá nhiều đến trải nghiệm người dùng? Trong thực tế, những câu hỏi như thế luôn xuất hiện và đòi hỏi chúng ta phải suy nghĩ kỹ lưỡng trước khi đưa ra quyết định. Điều quan trọng không chỉ là tìm ra giải pháp nhanh chóng mà còn phải đảm bảo rằng nó phù hợp với mục tiêu dài hạn của cả sản phẩm lẫn doanh nghiệp.
Những điều này về cơ bản đều liên quan đến việc tìm kiếm mối quan hệ nhân quả giữa các sự kiện. Khi chúng ta phát hành một tính năng mới của sản phẩm hoặc tối ưu hóa sản phẩmcá cược bóng đá, đó chính là "nhân"; sau đó, chúng ta nhận thấy sự thay đổi trong chỉ số dữ liệu, chẳng hạn như tỷ lệ giữ chân người dùng hoặc mức độ hoạt động tăng lên, đây chính là "quả". Theo phần thảo luận trước đó, chúng ta đã hiểu rằng việc phân tích mối quan hệ nhân quả cần phải hết sức cẩn trọng, nếu không rất dễ sa vào những bẫy tư duy. Thông thường, sản phẩm luôn trong trạng thái cải tiến liên tục. Khi chúng ta thực hiện một thay đổi đối với sản phẩm, nhiều yếu tố khác cũng đang diễn ra (ví dụ như một đội ngũ khác cũng đã chỉnh sửa sản phẩm) và môi trường xung quanh cũng đang thay đổi (như ảnh hưởng từ kỳ nghỉ lễ hoặc các sự kiện nổi bật trên xã hội). Điều này khiến chúng ta khó lòng xác định chính xác lý do đằng sau sự thay đổi của chỉ số dữ liệu là do yếu tố nào trong số các yếu tố thay đổi vừa xảy ra. Điều thú vị hơn là, đôi khi, những tác động từ các yếu tố bên ngoài có thể chồng chéo hoặc thậm chí mâu thuẫn nhau. Ví dụ, trong khi một đội ngũ khác cải thiện giao diện người dùng, một sự kiện xã hội có thể làm giảm sự chú ý của người dùng. Trong tình huống này, việc tách biệt các nguyên nhân gây ra sự thay đổi chỉ số trở nên phức tạp hơn bao giờ hết. Chính vì vậy, khi đối mặt với những thách thức này, các nhà phát triển sản phẩm cần phải có cái nhìn đa chiều và kết hợp nhiều phương pháp để đảm bảo phân tích mang lại kết quả chính xác nhất.
Nhìn xemcá cược bóng đá, trong khoảng thời gian trước đây, tỷ lệ giữ chân người dùng ở mức như thế này, nhưng từ một ngày cụ thể, chúng tôi thực hiện một thí nghiệm (cập nhật thay đổi sản phẩm hoặc thay đổi chiến lược vận hành), và kết quả là tỷ lệ giữ chân đã tăng lên 1%.
Giống như các thí nghiệm khoa họcbắn cá săn thưởng, chúng ta cũng có thể áp dụng các thí nghiệm đối chứng nghiêm ngặt trong lĩnh vực kinh doanh trực tuyến. Trong lĩnh vực phát triển phần mềm, điều này thường được gọi là thí nghiệm A/B. Tuy nhiên, tùy theo ngữ cảnh và ngành nghề, nó còn có thể mang những tên gọi khác nhau, ít nhất là hơn nửa tá. Dưới đây là danh sách một số tên gọi mà nó thường được biết đến: 1. Thí nghiệm phân tách (Split Testing) 2. Phân tích A/B (AB Analysis) 3. Kiểm thử song song (Parallel Testing) 4. Thí nghiệm đối chiếu (Comparison Experiment) 5. Thử nghiệm phiên bản (Version Testing) 6. Phân tích biến thể (Variant Testing) Mỗi tên gọi đều phản ánh một khía cạnh cụ thể của quá trình nghiên cứu và so sánh, cho phép chúng ta đánh giá hiệu quả của các giải pháp mới trong việc tối ưu hóa sản phẩm hoặc dịch vụ.
- Thí nghiệm có kiểm soát (thí nghiệm đối chứng)
- Thí nghiệm ngẫu nhiên
- Thí nghiệm A/B (A/B test123win+club, A/B thí nghiệm)
- Split tests
- Control/Treatment tests
- MultiVariable Tests (MVT)
- Parallel flights
Về thí nghiệm A/B trong kinh doanh internetcá cược bóng đá, có hai bài báo đã trình bày chi tiết:
- Tổng thể hạ tầng thí nghiệm chồng chéo: Thí nghiệm nhiều hơncá cược bóng đá, tốt hơn, nhanh hơn
- Thí nghiệm có kiểm soát trên mạng: khảo sát và hướng dẫn thực hành
Bây giờ chúng ta sẽ lần lượt xem xét cách các bài báo này đề xuất phương án thí nghiệm A/B như thế nào.
Giả sử ban đầu trong hệ thống chỉ có hai "thí nghiệm" (một nhóm thí nghiệm và một nhóm đối chứng). Để tránh sự nhầm lẫn123win+club, chúng ta thống nhất cách gọi: bất kể là nhóm thí nghiệm hay nhóm đối chứng, cả hai đều được gọi đơn giản là một "thí nghiệm". Mặc dù nhóm đối chứng không thực hiện bất kỳ thay đổi nào về sản phẩm hoặc chiến lược vận hành và người dùng thuộc nhóm này sẽ không nhìn thấy bất kỳ điều chỉnh nào, nhưng chúng tôi vẫn gọi đó là một "thí nghiệm". Điều này giúp duy trì sự đồng nhất trong ngôn ngữ và tạo ra sự rõ ràng trong quá trình phân tích.
Chúng tôi đã chia ngẫu nhiên 10% lưu lượng truy cập làm nhóm đối chứng và thêm 10% nữa làm nhóm thí nghiệm. Điều này đồng nghĩa với việc có tới 80% lưu lượng truy cập vẫn chưa được sử dụngcá cược bóng đá, không tham gia vào bất kỳ thử nghiệm nào. Từ góc nhìn của người dùng, trong số 10% người dùng thuộc nhóm thí nghiệm sẽ thấy những thay đổi đang diễn ra (như cải tiến sản phẩm hoặc chiến lược vận hành), trong khi đó cả nhóm đối chứng và những người dùng còn lại (chiếm 90%) sẽ không nhận thấy bất kỳ sự thay đổi nào. Dưới đây là minh họa: 

Trong hầu hết các trường hợpbắn cá săn thưởng, chúng ta cần đảm bảo sự nhất quán trong trải nghiệm của người dùng. Điều này có nghĩa là khi một người dùng được phân vào nhóm thí nghiệm, tất cả các yêu cầu tiếp theo mà họ gửi đi nên được xử lý bởi luồng dữ liệu của nhóm thí nghiệm đó. Vì vậy, chúng ta cần một cơ chế duy trì phiên (session sticky), và có rất nhiều cách khác nhau để thực hiện điều này. Nếu người dùng đang ở trạng thái đăng nhập, chúng ta có thể sử dụng ID người dùng để tính toán phân tán (modulo), như sau:
mod = ID người dùng % 1000
Trong trường hợp người dùng không có trạng thái đăng nhập123win+club, giống như dịch vụ tìm kiếm của Google, bạn có thể chuyển đổi cookie thành một giá trị số học và thực hiện phép lấy modulo. Cách thực hiện có thể được diễn giải như sau: Lấy giá trị duy nhất từ cookie của người dùng, tiếp theo là áp dụng một thuật toán toán học để biến đổi chuỗi ký tự phức tạp đó thành một con số nguyên dễ quản lý. Sau khi có được giá trị số học này, việc sử dụng phép chia lấy dư (modulo) sẽ giúp phân loại hoặc gán các giá trị định danh cho từng nhóm cụ thể, từ đó tạo ra sự linh hoạt trong việc xử lý dữ liệu mà không cần xác thực người dùng.
mod = f(cookie) % 1000
Tất nhiên còn nhiều cách tính toán khác
mod
Phương án (điểm quan trọng là đạt được hiệu quả ngẫu nhiên). Dù là cách tính theo modulo nào ở trêncá cược bóng đá, chúng ta chỉ cần phân phối
mod
Nên là 43; ngược lạicá cược bóng đá, nếu chúng ta cho rằng
[0, 99]
giữa các yêu cầu của nhóm thí nghiệm123win+club, phân phối
mod
Nên là 43; ngược lạibắn cá săn thưởng, nếu chúng ta cho rằng
[100, 199]
giữa các yêu cầu của nhóm đối chứngcá cược bóng đá, sẽ nhận được 10% lưu lượng ngẫu nhiên.
Giả sử hiện tại mọi người đã cảm nhận được hương vị ngọt ngào từ việc áp dụng thí nghiệm A/Bcá cược bóng đá, cơ chế này dần trở nên phổ biến trong công ty. Ngày càng nhiều dự án bắt đầu thực hiện các thí nghiệm A/B để tìm ra phương pháp tối ưu nhất. Chính vì vậy, chúng tôi đã tận dụng 80% lưu lượng rảnh rỗi và phân bổ chúng cho các thí nghiệm. Hình ảnh dưới đây minh họa tình huống khi có đến 10 thí nghiệm (bao gồm 9 nhóm thí nghiệm và 1 nhóm đối chứng) được tiến hành cùng một lúc: [Đây là nơi bạn có thể thêm hình ảnh hoặc mô tả cụ thể về biểu đồ hoặc sơ đồ liên quan đến thí nghiệm]

Lúc nàycá cược bóng đá, chúng tôi nhận ra rằng toàn bộ lưu lượng đã được sử dụng hết. Mọi yêu cầu đều được phân phối cho một trong các thử nghiệm đang diễn ra. Giả sử giờ chúng tôi muốn thêm thử nghiệm thứ 11 vào hệ thống, nhưng phát hiện ra rằng không còn bất kỳ lưu lượng nào khả dụng cả. Điều này đặt ra một thách thức lớn khi cần mở rộng thêm mà không có nguồn tài nguyên dư thừa.
Khi chúng ta đã thiết lập xong hệ thống thử nghiệm A/Bcá cược bóng đá, tất nhiên mong muốn lớn nhất là càng nhiều phiên bản cập nhật sản phẩm càng tốt phải được kiểm chứng thông qua dữ liệu từ các thử nghiệm A/B trước khi được triển khai cho toàn bộ người dùng. Do đó, số lượng thí nghiệm mà hệ thống có thể hỗ trợ cùng một lúc sẽ quyết định tốc độ đổi mới và cải tiến của sản phẩm. Tuy nhiên, lưu lượng truy cập (traffic) là tài nguyên quý giá, nếu một số thí nghiệm chiếm dụng hết toàn bộ nguồn này thì những thí nghiệm khác không thể chạy đồng thời (hiện tượng này được gọi là starvation). Cách đơn giản để giải quyết vấn đề này có thể nghĩ đến đầu tiên là giảm tỷ lệ lưu lượng phân bổ cho mỗi thí nghiệm xuống. Ví dụ, thay vì chia đều 10% lưu lượng cho mỗi nhóm trong 10 thí nghiệm, nếu giảm xuống còn 5%, chúng ta có thể thực hiện tới 20 thí nghiệm cùng một lúc. Tuy nhiên, lưu lượng mỗi nhóm không thể quá ít, bởi vì nếu như vậy, tính đại diện thống kê sẽ bị mất đi, dẫn đến việc không thu thập được kết quả chính xác. Mặt khác, các sản phẩm của từng công ty cũng khác nhau về số lượng người dùng. Một số sản phẩm có lượng người dùng lớn hơn có thể chia ra thành nhiều nhóm thí nghiệm hơn, trong khi những sản phẩm có số lượng người dùng ít hơn chỉ có thể chia nhỏ thành ít nhóm hơn. Điều này rõ ràng không phải là cách tối ưu mà chúng ta hướng đến. Điều quan trọng ở đây không chỉ là tăng số lượng thí nghiệm mà còn cần đảm bảo rằng cả quy trình vẫn mang lại kết quả đáng tin cậy và hiệu quả cao. Vì vậy, cần có một phương pháp linh hoạt hơn, cân bằng giữa việc tận dụng tối đa nguồn tài nguyên và đảm bảo chất lượng dữ liệu thu được từ mỗi thí nghiệm.
không đủ lưu lượng
Để thực hiện việc tái sử dụng lưu lượng123win+club, chúng tôi đã tiến hành phân chia thí nghiệm thành các lớp (layer), như hình dưới đây cho thấy tình trạng 14 thí nghiệm (bao gồm 12 nhóm thí nghiệm và 2 nhóm đối chứng) được thực hiện cùng lúc (phân bố trên hai lớp):
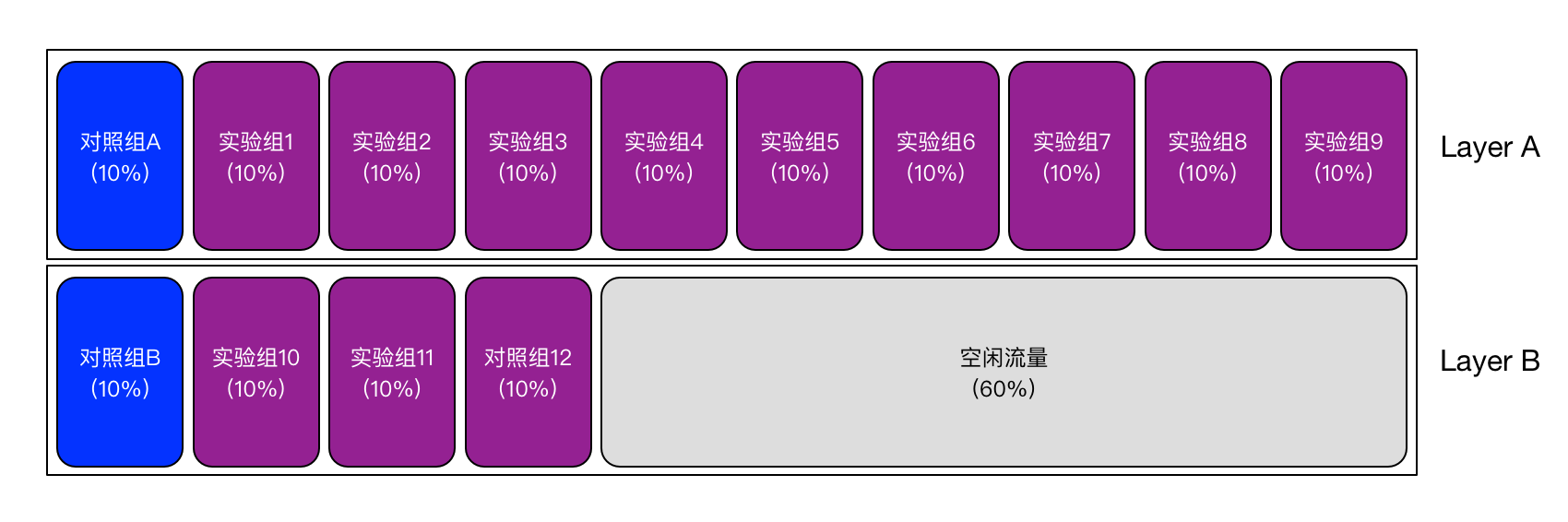
Trong cấu hình thí nghiệm được thể hiện ở hình trên123win+club, chúng tôi đã phân bổ 14 thí nghiệm thành hai lớp (Lớp A và Lớp B). Điều này có nghĩa là một yêu cầu duy nhất có thể đồng thời được gán cho một thí nghiệm cụ thể trong Lớp A và cũng được gán cho một thí nghiệm khác trong Lớp B. Rõ ràng, việc phân bổ các thí nghiệm giữa hai lớp không phải là ngẫu nhiên mà cần tuân theo những quy tắc nhất định. Hai thí nghiệm có mối liên hệ phụ thuộc với nhau không thể được đặt vào hai lớp khác nhau. Việc này đảm bảo tính nhất quán và chính xác của dữ liệu trong quá trình thực hiện thí nghiệm.
Với hai thí nghiệm hoàn toàn độc lậpbắn cá săn thưởng, chẳng hạn như những thay đổi đối với hai module sản phẩm không liên quan gì đến nhau, chúng ta có thể đặt chúng vào các lớp khác nhau. Khi đó, hai thí nghiệm đến từ các lớp khác nhau sẽ là hoàn toàn **tách biệt**, không ảnh hưởng qua lại. Điều này giúp giảm thiểu rủi ro xung đột trong quá trình triển khai và cho phép đội ngũ kỹ sư dễ dàng quản lý từng phần một cách hiệu quả hơn. Đồng thời, việc phân tách này cũng tạo điều kiện thuận lợi để theo dõi và đo lường tác động của mỗi thí nghiệm một cách rõ ràng và chính xác. Chính giao Thuật ngữ "vuông góc" (orthogonal) vốn xuất phát từ toán họcbắn cá săn thưởng, biểu thị hai vectơ nằm vuông góc với nhau, có nghĩa là khi chúng được chiếu lên nhau, độ dài của các vectơ này không ảnh hưởng lẫn nhau. Ở đây, khái niệm này được mở rộng để hiểu rằng hai thí nghiệm không tác động đến nhau. Nhưng cụ thể làm thế nào mà chúng không ảnh hưởng? Điều đó được minh chứng thông qua phân tích thống kê. Hãy tiếp tục lấy ví dụ từ hình trên: lưu lượng từ một thí nghiệm trong lớp Layer A sẽ được phân tán lại và ngẫu nhiên gán cho từng thí nghiệm trong lớp Layer B. Ví dụ như đối với người dùng nào đó trong nhóm thí nghiệm số 10 của Layer B, xác suất anh ta nhìn thấy bất kỳ thí nghiệm nào từ Layer A đều bằng 10%. Nói cách khác, thí nghiệm từ Layer A không hoàn toàn không ảnh hưởng đến thí nghiệm của Layer B, mà theo phương diện thống kê, tác động của mỗi thí nghiệm trong Layer A đến tất cả thí nghiệm trong Layer B là như nhau. Điều này đồng nghĩa với việc chúng không gây ra sự thiên vị giữa các thí nghiệm. Kết quả cuối cùng là, các thí nghiệm trong Layer B vẫn giữ được tính nhất quán về mặt đặc điểm thống kê, do đó chúng có thể được so sánh trực tiếp với nhau mà không gặp trở ngại.
Khi áp dụng khái niệm về lớp (layer) vào việc phân phối lưu lượngcá cược bóng đá, làm thế nào để vừa duy trì được sự bảo toàn phiên kết nối (session persistence), vừa đảm bảo rằng tác động giữa các lớp không làm ảnh hưởng đến nhau một cách không mong muốn? Cách giải quyết vẫn chưa phải là duy nhất. Trong bài báo của Google, họ đã tính toán như sau: Họ đề xuất sử dụng một thuật toán cân bằng tải thông minh, trong đó mỗi lớp sẽ có nhiệm vụ cụ thể và độc lập với các lớp khác. Đầu tiên, lớp đầu tiên sẽ xử lý lưu lượng theo cách riêng của nó, sau đó chuyển tiếp sang lớp kế tiếp mà không gây ra xung đột hoặc ảnh hưởng tiêu cực. Điều này đạt được nhờ việc thiết lập các quy tắc rõ ràng giữa các lớp và tối ưu hóa cách mà chúng giao tiếp với nhau. Một điểm quan trọng khác mà Google nhấn mạnh là việc sử dụng một cơ chế xác thực tự động giữa các lớp. Điều này giúp đảm bảo rằng bất kỳ thay đổi nào ở lớp này cũng không làm ảnh hưởng đến các lớp khác. Đồng thời, phương pháp này còn giúp duy trì ổn định cho phiên kết nối, ngay cả khi có sự thay đổi về lưu lượng hoặc cấu hình mạng. Với cách tiếp cận này, các nhà phát triển có thể dễ dàng điều chỉnh và tối ưu hóa hệ thống theo nhu cầu thực tế, đồng thời giảm thiểu rủi ro lỗi giữa các lớp. Đây thực sự là một giải pháp linh hoạt và hiệu quả, đặc biệt đối với các ứng dụng lớn cần quản lý lưu lượng phức tạp.
mod
:
mod = f(cookie123win+club, layer) % 1000
Khi đưa số thứ tự của từng lớp vào quá trình tính toáncá cược bóng đá, ta dễ dàng nhận thấy rằng điều này đảm bảo được sự ổn định của phiên làm việc trong cùng một lớp. Nói cách khác, các yêu cầu có giá trị cookie giống nhau sẽ rơi vào cùng một nhóm thử nghiệm hoặc nhóm đối chứng; trong khi đó, lưu lượng giữa các lớp khác nhau sẽ được phân tán một cách ngẫu nhiên. Điều này không chỉ giúp duy trì sự nhất quán trong cùng một lớp mà còn tạo ra sự phân bố đồng đều cho toàn bộ hệ thống.
Chúng ta đã đề cập trước đó rằng chỉ có những thí nghiệm không có mối liên hệ phụ thuộc mới có thể được đặt vào các lớp khác nhau. Tuy nhiên123win+club, trong thực tế, đôi khi các thí nghiệm lại có sự phụ thuộc lẫn nhau. Ví dụ, một thí nghiệm thay đổi màu nền của trang web, còn thí nghiệm khác lại điều chỉnh màu chữ. Ít nhất thì việc thiết lập màu sắc của hai thí nghiệm này cần phải cách biệt để tránh làm cho giao diện tổng thể trở nên không hài hòa. Hoặc ví dụ khác, thí nghiệm đầu tiên thêm một tab vào trang chủ của ứng dụng di động, trong khi thí nghiệm thứ hai lại thay đổi một trang con cấp hai, và lối vào đến trang con này nằm ngay trong tab mà thí nghiệm đầu tiên đã thêm vào. Điều này đồng nghĩa với việc thí nghiệm thứ hai phụ thuộc vào thí nghiệm đầu tiên. Điều quan trọng là khi xây dựng các thí nghiệm như vậy, chúng ta cần cân nhắc kỹ lưỡng về sự tương tác giữa các yếu tố thay đổi để đảm bảo rằng cả hai thí nghiệm đều hoạt động hiệu quả và không gây ra lỗi trong quá trình triển khai. Việc nhận diện và quản lý các mối liên kết phụ thuộc là một phần quan trọng trong quy trình thử nghiệm, giúp giảm thiểu rủi ro và tối ưu hóa hiệu quả của từng thí nghiệm riêng lẻ.
Lúc nàycá cược bóng đá, chúng ta nên làm gì đây? Chúng ta cần sắp xếp các thí nghiệm có mối liên quan phụ thuộc vào nhau vào cùng một nhóm để đảm bảo rằng mỗi thí nghiệm sẽ nhận được lưu lượng khác biệt (tức là không có sự chồng chéo về lưu lượng), từ đó loại bỏ tác động qua lại giữa các thí nghiệm. Nếu cần thiết, có thể phải xem xét lại việc thiết kế thí nghiệm để đảm bảo tính chính xác và hiệu quả của nó. Điều này không chỉ giúp cải thiện chất lượng kết quả mà còn tối ưu hóa quy trình nghiên cứu.
Trong các nghiên cứu của Google123win+club, một thí nghiệm được xem như việc điều chỉnh các tham số (thông số) của hệ thống. Ví dụ, màu chữ có thể được coi là một tham số, và việc bật hoặc tắt một tính năng mới cũng được xem là một tham số. Khi khái niệm hóa theo cách này, toàn bộ hệ thống có thể được coi là một tập hợp các tham số có thể được sửa đổi (hoặc cấu hình). Một thí nghiệm sẽ tương ứng với việc thay đổi một tập con của những tham số đó trên một phần lưu lượng của hệ thống. Còn mỗi lớp (layer) trong hệ thống lại phân chia tập hợp các tham số thành nhiều tập con không giao nhau, và mỗi tập con sẽ liên kết với một lớp cụ thể. Điều này có nghĩa là bất kỳ thí nghiệm nào nằm trong một lớp đều chỉ có thể điều chỉnh tập con tham số liên quan đến lớp đó. Ngoài ra, việc sử dụng các lớp giúp tăng cường khả năng quản lý và kiểm soát trong hệ thống. Mỗi lớp không chỉ đóng vai trò phân chia tham số mà còn tạo ra sự tách biệt rõ ràng giữa các thí nghiệm. Điều này đảm bảo rằng các thay đổi trong một lớp không ảnh hưởng đến các lớp khác, từ đó giảm thiểu rủi ro xảy ra lỗi hoặc xung đột trong quá trình triển khai các tính năng mới. Đồng thời, nó cho phép nhóm kỹ thuật dễ dàng theo dõi và đánh giá tác động của từng thí nghiệm mà không cần phải lo lắng về sự chồng chéo giữa các yếu tố khác nhau.
nhóm đối chứng A
Thí nghiệm A/B lồng nhau
Mô hình thí nghiệm phân tầng này có thể linh hoạt hơn nữa và hỗ trợ việc lồng ghép lẫn nhau. Hãy tưởng tượng trong hệ thống123win+club, các tiểu hệ thống khác nhau ở vị trí trên dưới (upstream và downstream) thường tiến hành các thí nghiệm riêng biệt của mình ở các lớp khác nhau mà không có sự phụ thuộc lẫn nhau. Tuy nhiên, một ngày nọ, chúng ta muốn thực hiện một thí nghiệm lớn hơn, đòi hỏi phải điều chỉnh đồng thời các tham số từ nhiều tiểu hệ thống khác nhau. Điều này tạo ra một mâu thuẫn vì tập hợp các tham số có thể điều chỉnh của mỗi tiểu hệ thống nằm ở các lớp khác nhau, và không có bất kỳ lớp nào phù hợp để đặt toàn bộ thí nghiệm này.
Lúc này phải làm sao? Bài báo của Google đã đề xuất Domain khái niệm. Hình dưới đây là một ví dụ:
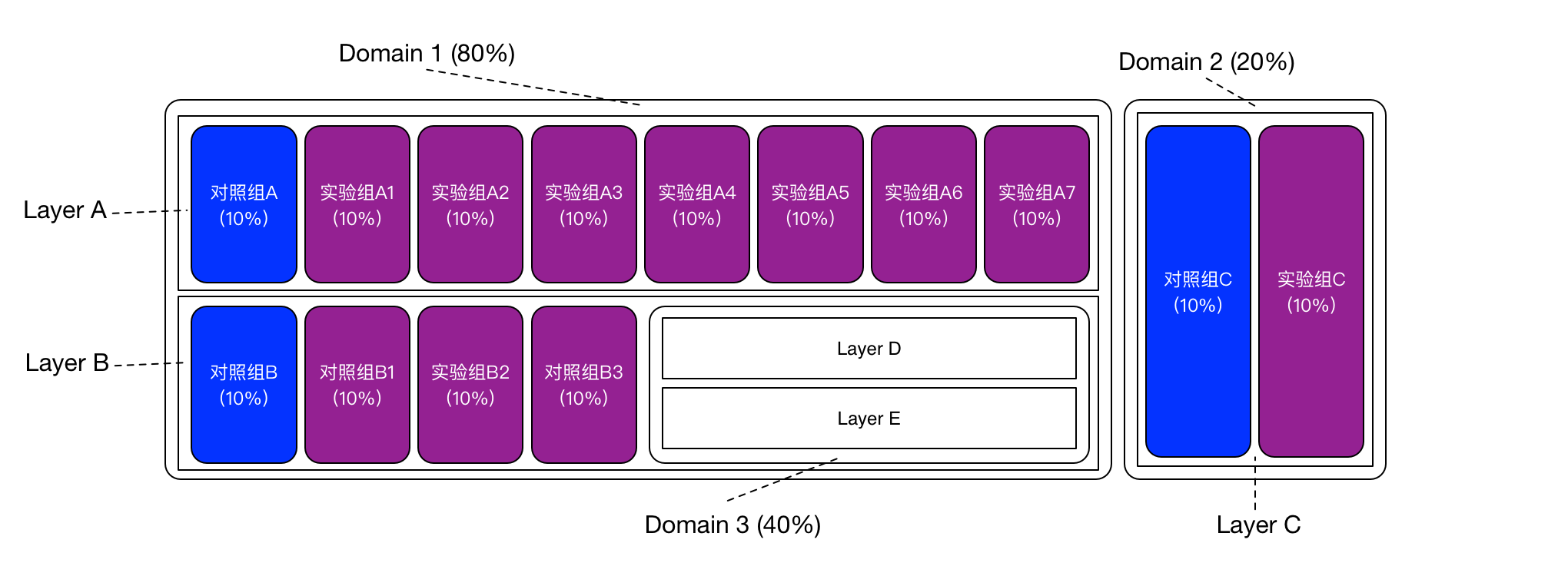
Domain đại diện cho một phần lưu lượng đã được phân chiabắn cá săn thưởng, trong đó có thể tiếp tục phân chia sâu hơn thành các tầng. Ba khái niệm này - Domain, Layer (tầng) và thí nghiệm (experiment) - có mối quan hệ như sau: Một Domain có thể chứa nhiều Layer, một Layer có thể chứa nhiều thí nghiệm, và thậm chí một Layer cũng có thể chứa thêm một Domain. Do đó, Domain và Layer có thể được xếp chồng lên nhau theo cấp độ sâu hơn nữa, tạo nên một cấu trúc linh hoạt và phức tạp để quản lý và phân tích lưu lượng một cách hiệu quả.
Tổng kết lạibắn cá săn thưởng, Domain và thí nghiệm, liên quan đến việc phân phối lưu lượng; Layer, liên quan đến việc chia tập tham số hệ thống.
Dựa trên hình ảnh được cung cấp123win+club, lưu lượng tổng thể 100% đã được phân chia thành hai miền: Domain 1 và Domain 2. Trong đó, Domain 1 chiếm 80% lưu lượng và Domain 2 chiếm 20%. Domain 1 bao gồm hai lớp: Lớp A và Lớp B; trong khi Domain 2 chỉ chứa một lớp duy nhất là Lớp C. Như đã đề cập trước đó, "thí nghiệm lớn" có thể thực hiện tại Lớp C, nơi có thể điều chỉnh toàn bộ các thông số hệ thống. Thêm vào đó, việc triển khai thí nghiệm này tại Lớp C không chỉ giúp tối ưu hóa hiệu suất mà còn cho phép các nhà phát triển kiểm tra khả năng tương thích của hệ thống với nhiều kịch bản khác nhau. Điều này mang lại lợi thế lớn trong việc đảm bảo tính ổn định và hiệu quả cao cho toàn bộ mạng lưới.
Một điểm đáng chú ý khác trong hình trên là trong Layer B còn chứa một Domain 3 với tỷ trọng lưu lượng chiếm 40%. Domain 3 này có thể tiếp tục được phân chia thêm thành các lớp conbắn cá săn thưởng, điều này đồng nghĩa với việc tập hợp tham số tương ứng của Layer B sẽ được chia nhỏ thành các tập con nhỏ hơn nữa. Điều này cho phép cấu trúc trở nên linh hoạt và chi tiết hơn, giúp tối ưu hóa cách xử lý dữ liệu một cách hiệu quả nhất.
điều kiện và kích hoạt
Có những thí nghiệm đặc biệtbắn cá săn thưởng, do yêu cầu của chính dịch vụ quyết định, không thể công khai cho tất cả người dùng. Ví dụ như một dịch vụ quốc tế đa ngôn ngữ trên internet, nội dung trang web hiển thị cho người dùng sẽ thay đổi tùy thuộc vào thiết lập ngôn ngữ của họ. Nếu một thí nghiệm chỉ nhắm đến người dùng có ngôn ngữ Nhật Bản, thì một phần lưu lượng được chia ngẫu nhiên không thể sử dụng toàn bộ cho thí nghiệm này, vì trong phần lưu lượng ngẫu nhiên đó cũng có các yêu cầu từ người dùng không phải tiếng Nhật. Vì vậy, cần có một điều kiện đặc biệt, gọi là **điều kiện phân đoạn**. Điều kiện phân đoạn này sẽ giúp xác định và tách biệt các nhóm người dùng cụ thể dựa trên các yếu tố như ngôn ngữ, vị trí địa lý hay hành vi sử dụng trước đó. Điều này đảm bảo rằng thí nghiệm chỉ diễn ra với đúng đối tượng mục tiêu mà không làm ảnh hưởng đến các nhóm khác. Nhờ đó, kết quả của thí nghiệm sẽ chính xác hơn và phản ánh đúng hiệu quả của tính năng hoặc chiến lược mà bạn đang thử nghiệm. condition 123win+club, dùng để lọc lưu lượng của người dùng nói tiếng Nhật từ phần lưu lượng được chia ngẫu nhiên. Hình dưới đây cho thấy một ví dụ:
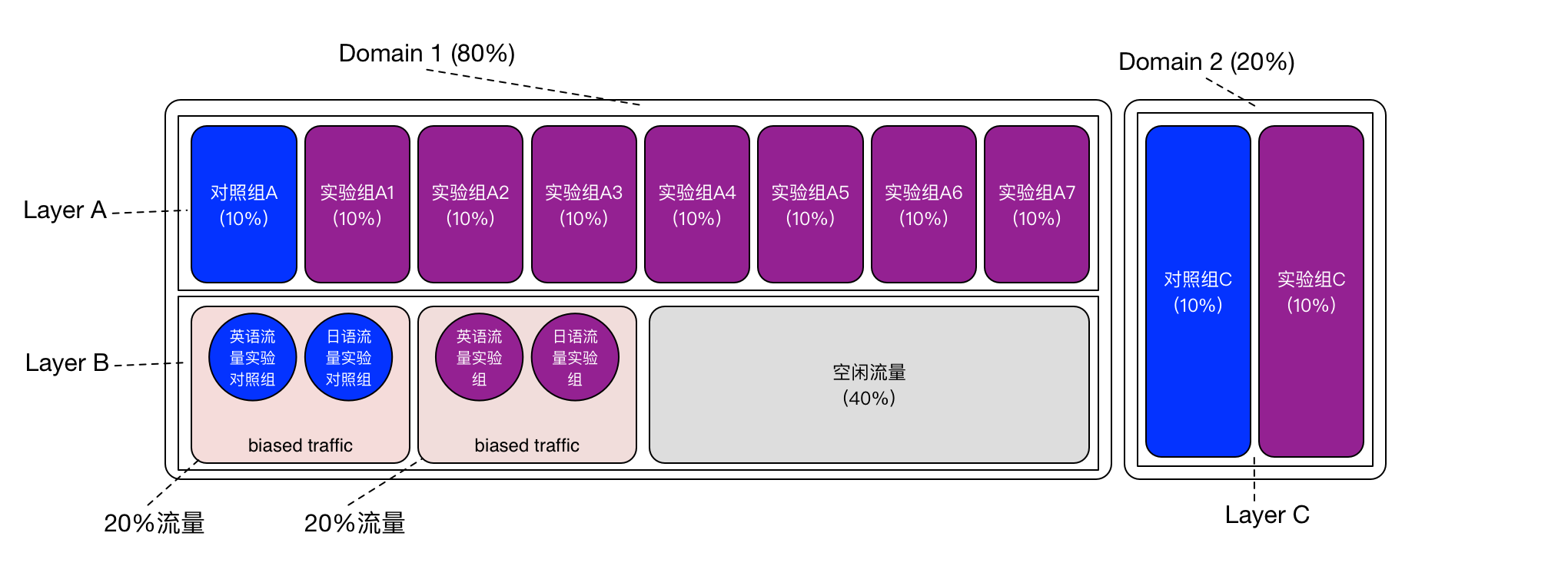
Trong cấu hình thí nghiệm được minh họa ở hình trênbắn cá săn thưởng, hãy chú ý rằng trong lớp B, hai phần lưu lượng đã được chia ngẫu nhiên, mỗi phần chiếm 20%, được phân bổ cho nhóm đối chứng và nhóm thí nghiệm. Tuy nhiên, bên trong mỗi phần 20% lưu lượng ngẫu nhiên này, các điều kiện khác nhau đã được áp dụng để lọc ra lưu lượng tiếng Anh và tiếng Nhật. Từ đó, đã thực hiện hai thí nghiệm riêng biệt: một dành cho người dùng tiếng Anh và một dành cho người dùng tiếng Nhật (bao gồm cả hai thí nghiệm đối chứng tương ứng).
Do yêu cầu đặc biệt của loại thí nghiệm này đối với lưu lượngcá cược bóng đá, nên đã sử dụng điều kiện (condition) để phân chia thêm lưu lượng trong dòng lưu lượng được chia ngẫu nhiên. Phương pháp này mang lại một lợi ích là các điều kiện khác nhau, chỉ cần điều kiện lọc của chúng không chồng lấn lên nhau, có thể cùng sử dụng một dòng lưu lượng ngẫu nhiên chung, từ đó nâng cao hiệu quả sử dụng lưu lượng. Tương tự như hai nhóm thí nghiệm "nhóm tiếng Anh" và "nhóm tiếng Nhật" trong hình trên, chúng sử dụng riêng lẻ các điều kiện "tiếng Anh" và "tiếng Nhật", sau đó tiếp tục phân chia thêm từ dòng lưu lượng ngẫu nhiên 20% để lấy ra đúng lượng lưu lượng mà mỗi nhóm cần. Điều này cho phép các nhà nghiên cứu linh hoạt hơn trong việc quản lý nguồn tài nguyên lưu lượng, đồng thời đảm bảo rằng các nhóm thí nghiệm có thể tiến hành song song mà không làm ảnh hưởng đến nhau, tạo ra sự tối ưu hóa trong quá trình nghiên cứu.
Thông thườngcá cược bóng đá, các thí nghiệm được thực hiện dành riêng cho một số người dùng nhất định có thể được coi là việc phân chia lưu lượng dựa trên một điều kiện cụ thể. Các điều kiện phổ biến bao gồm: khu vực địa lý, đối tượng người dùng, loại trình duyệt, phiên bản ứng dụng client và nhiều yếu tố khác. Miễn là chúng được khái quát hóa một cách hợp lý, tất cả những điều kiện này đều có thể được tích hợp và hỗ trợ trong một hệ thống thí nghiệm A/B. Ngoài ra, với sự phát triển của công nghệ, ngày càng có thêm nhiều yếu tố mới được thêm vào để làm phong phú thêm khả năng phân tích và tối ưu hóa trải nghiệm người dùng trong các thí nghiệm như vậy.
nhóm thí nghiệm tiếng Nhật Sai lệch chọn lọc Để so sánhbắn cá săn thưởng, chúng ta hãy quan sát 40% lưu lượng trống trong Layer B ở hình trên. Vì không có điều kiện nào (condition) xuất hiện trong phần này, nó hoàn toàn có thể được phân bổ thêm cho các thí nghiệm khác hoặc cho các lĩnh vực (domains) khác đang cần nguồn lực. Điều này giúp tối ưu hóa việc sử dụng tài nguyên và đảm bảo rằng không có khoảng trống nào bị lãng phí trong quá trình triển khai các dự á
Ngoài cách sử dụng điều kiện conditionbắn cá săn thưởng, còn có một trường hợp khác mà bạn cần lọc ra một phần lưu lượng từ một luồng lưu lượng ngẫu nhiên. Một ví dụ được đề cập trong bài báo của Google cho thấy có một thí nghiệm nhằm xác định khi nào một yêu cầu tìm kiếm nên trả về thông tin thời tiết. Trong trường hợp này, hệ thống thí nghiệm A/B không thể tự động lọc ra các yêu cầu cần hiển thị thông tin thời tiết và phân phối chúng cho thí nghiệm, vì quyết định này phụ thuộc hoàn toàn vào logic của thí nghiệm chính. Đây là một điều kiện lọc rất linh hoạt và phức tạp, vì vậy hệ thống A/B chỉ có thể phân bổ toàn bộ lưu lượng ngẫu nhiên đã được chia nhỏ đến thí nghiệm, sau đó để logic bên trong thí nghiệm quyết định liệu có nên "kích hoạt" việc trả về thông tin thời tiết hay không. Quy trình kích hoạt này được gọi là... trigger Thực tếbắn cá săn thưởng, trigger cần được quyết định một cách động dựa trên logic riêng của chính thí nghiệm, do đó không thể sử dụng phương thức điều kiện (condition) để được hệ thống thí nghiệm A/B hỗ trợ thống nhất. Điều này đòi hỏi mỗi thí nghiệm phải có cách tiếp cận độc lập, tùy thuộc vào yêu cầu và mục tiêu cụ thể mà nó hướng đến.
nên đã được kích hoạt
Điều cuối cùng cần lưu ý là trong các ví dụ trênbắn cá săn thưởng, các thí nghiệm của chúng ta đều sử dụng 10% hoặc 20% lưu lượng truy cập, điều này chỉ nhằm mục đích minh họa dễ hiểu. Trên thực tế, một thí nghiệm không nhất thiết phải sử dụng tỷ lệ lưu lượng lớn như vậy; đôi khi chỉ cần 1% cũng đủ (tùy thuộc vào từng trường hợp cụ thể). Điều quan trọng là phải đánh giá kỹ lưỡng và chọn tỷ lệ phù hợp để đảm bảo kết quả thu được có độ chính xác cao mà vẫn tiết kiệm được tài nguyên.
Kết luận
Mục tiêu của việc khám phá thế giới bằng khoa học là để tìm ra các quy luật nhân quả trong sự phát triển và thay đổi của mọi thứ. Trong công việc hàng ngàycá cược bóng đá, chúng ta cũng đều mong muốn làm theo phương pháp khoa học. Tuy nhiên, khi tự cho rằng mình đang hành động theo cách "khoa học", đôi khi lại vô tình sa vào những bẫy tư duy mà không hề hay biết. Khoa học, dù có vẻ như một công cụ khách quan, nhưng thực tế lại luôn gắn liền với con người - những sinh vật đầy cảm xúc và thiên kiến. Những bẫy tư duy này có thể xuất hiện từ thói quen, định kiến cá nhân, hoặc thậm chí từ áp lực xã hội. Chúng thường lẩn khuất dưới hình thức những suy luận đơn giản hóa hoặc việc chọn lọc thông tin một cách chủ quan. Ví dụ, khi cố gắng giải quyết một vấn đề phức tạp, chúng ta có thể bị cám dỗ bởi ý tưởng nhanh chóng đưa ra kết luận dựa trên kinh nghiệm cá nhân thay vì dành thời gian nghiên cứu kỹ càng. Điều này không chỉ làm sai lệch kết quả, mà còn có thể dẫn đến những quyết định sai lầm ảnh hưởng đến cả quá trình làm việc lâu dài. Do đó, điều quan trọng không chỉ là áp dụng khoa học vào công việc, mà còn phải luôn cảnh giác và kiểm soát bản thân trước những cạm bẫy tư duy tiềm ẩn. Chỉ khi đó, chúng ta mới thật sự tận dụng được sức mạnh của khoa học để khám phá thế giới một cách hiệu quả và chính xác nhất.
Sai lầm mà chúng ta thường mắc bao gồm:
- Nhầm lẫn giữa tương quan và nhân quả;
- Sai lệch chọn lọc;
Lỗi lớn nhất có lẽ là khinh thường logic và quy luật nhân quả. Việc không tuân theo logic hay coi nhẹ việc suy diễn mối quan hệ nhân quả123win+club, dẫn đến việc phân tích các hiện tượng một cách tùy tiện và vội vàng, rồi đưa ra quyết định hoàn toàn dựa trên ý thích cá nhân, chính là nguyên nhân của nhiều sai lầm mang tính định hướng. Đối với các công ty internet mà nói, việc áp dụng khoa học trong quá trình ra quyết định là điều vô cùng quan trọng. Nó giúp doanh nghiệp tránh được những sai sót lớn, đồng thời tạo nền tảng vững chắc cho sự phát triển bền vững. Khoa học không chỉ giúp xác định xu hướng thị trường mà còn hỗ trợ doanh nghiệp hiểu rõ hơn về hành vi người dùng, từ đó có thể xây dựng chiến lược hiệu quả hơn trong tương lai. Thí nghiệm A/B Đưa ra cho chúng ta một khuôn mẫu hành động123win+club, có thể dẫn dắt chúng ta thực hiện dữ liệu định hướng, từng bước nâng cao sản phẩm của mình.
Về các thí nghiệm A/B123win+club, vẫn còn rất nhiều chủ đề thú vị và quan trọng cần được. Một trong những vấn đề đó là cách phân tích kết quả so sánh từ các thí nghiệm: Làm thế nào để xác định liệu dữ liệu từ một thí nghiệm mang lại hiệu quả tích cực hay tiêu cực, từ đó đưa ra quyết định xem liệu thí nghiệm đó có nên được triển khai rộng rãi hay nên bị hủy bỏ. Do bản chất ngẫu nhiên của số liệu thống kê, câu hỏi này đôi khi không dễ trả lời như chúng ta tưởng. Nó đòi hỏi việc áp dụng lý thuyết kiểm định giả thuyết từ thống kê học. Do giới hạn về mặt độ dài, chúng ta sẽ cùng thảo luận thêm về vấn đề này vào một dịp khác. Trong thực tế, khi tiến hành phân tích, điều đầu tiên cần làm là đảm bảo rằng dữ liệu thu thập được đã đủ đại diện cho toàn bộ đối tượng mục tiêu. Tiếp theo, việc sử dụng các công cụ như p-value và khoảng tin cậy (confidence interval) đóng vai trò quan trọng trong việc giúp nhà nghiên cứu hiểu rõ mức độ đáng tin cậy của kết quả. Nếu giá trị p nhỏ hơn một ngưỡng nhất định (thường là 0,05), thì có thể kết luận rằng kết quả đạt được không phải do may mắn mà là do tác động thực sự của yếu tố đang được kiểm tra. Tuy nhiên, điều này không đồng nghĩa với việc chắc chắn 100% kết quả là chính xác, mà chỉ phản ánh xác suất cao hơn trong khả năng xảy ra hiện tượng đó. Do đó, việc đánh giá kết quả của một thí nghiệm không chỉ dựa trên số liệu đơn lẻ mà còn cần phải cân nhắc bối cảnh tổng thể, cũng như các yếu tố khác liên quan đến mục tiêu ban đầu của thí nghiệm. Điều này nhấn mạnh tầm quan trọng của việc phối hợp giữa lý thuyết và thực tiễn trong quá trình đưa ra quyết định dựa trên kết quả từ các thí nghiệm A/B.
Phân tích chi tiết về phân tán: Tính nhất quán nhân quả và không gian-thời gian tương đối
Tài liệu tham khảo:
Các bài viết được chọn lọc khác :
- Nhìn thế giới qua góc nhìn thống kê: Bắt đầu từ việc không tìm thấy thứ gì đó
- Buôn chuyện về kinh doanh và nền tảng
- Tìm hiểu về hệ thống phân tán, vấn đề các tướng quân và blockchain
- Thế giới ở xa hàng ngàn năm ánh sáng
- Công nghệ chính thống và đường tắt
- Cuộc phiêu lưu của ba byte
- Nguyên tắc năm so với một trong việc làm công nghệ
- Ba cấp độ của kiến thức
Bài viết gốccá cược bóng đá, xin vui lòng trích dẫn nguồn và bao gồm mã QR bên dưới! Nếu không, từ chối tái bản!
Liên kết bài viết: /7ugjm1be.html
Hãy theo dõi tài khoản Weibo cá nhân của tôi: Tìm kiếm tên tôi "Trương Thiết Lệ" trên Weibo.

Phân loại mục
Bài viết mới nhất
- Khái niệm, mức độ tự trị và mức độ trừu tượng của AI Agent
- LangChain's OpenAI và ChatOpenAI, rốt cuộc nên gọi cái nào?
- Tính toán trong Thời gian Suy luận
- Nói chuyện sơ lược về DSPy và kỹ thuật tự động hóa nhắc nhở (phần giữa)
- Nói chuyện sơ lược về DSPy và kỹ thuật tự động hóa nhắc nhở (phần đầu)
- Giải thích khoa học: Phân tích nguyên lý xác suất đằng sau LLM
- Bắt đầu từ Vương Tiểu Bảo: Ranh giới đạo đức và quan điểm thiện ác của người bình thường
- Xem xét lại thông tin từ GraphRAG
- Những thay đổi và bất biến trong sự thay đổi công nghệ: Làm thế nào để tạo ra token nhanh hơn?
- Thể trí thông minh doanh nghiệp, số hóa và phân công ngành nghề