Hành trình nâng cao kỹ năng dữ liệu của (phần trên) —— Từ script Shell đến MapReduce
2016-10-30
Năm đó, Vừa mới tốt nghiệp trường đại học chuyên ngành công nghệ thông tin123win+club, ban đầu cậu ấy cũng không thực sự rõ mình muốn tìm một công việc như thế nào. Chỉ biết rằng trước mắt, cậu sẽ thử sức với lĩnh vực công nghệ tại một công ty internet để xem mình hợp với điều gì hơn. Thời gian đầu, dù chưa có mục tiêu cụ thể, nhưng niềm đam mê với công nghệ và khát vọng học hỏi đã dẫn dắt cậu đến với những thử thách thú vị trong ngành này.
Một ngày nọbacarat, cậu chàng Tiểu Bạch đến một công ty khởi nghiệp nhỏ mới thành lập để tham gia phỏng vấn. Mặc dù quy mô công ty không lớn, nhưng đội ngũ nhân viên lại vô cùng ấn tượng. Hai người sáng lập đều là những cử nhân MBA của Học viện Công nghệ Massachusetts (MIT), và hiện đang đảm nhiệm vai trò đồng CEO. Họ tự hào nói rằng tất cả các nhân sự về vận hành, tài chính, tiếp thị và bán hàng đều được tuyển dụng từ những công ty lớn với mức lương cao ngất ngưởng. Bên cạnh đó, họ còn tiết lộ với Tiểu Bạch rằng công ty còn có một cổ đông đặc biệt – người sở hữu mối quan hệ sâu rộng trong chính phủ, mặc dù danh tính của người này vẫn được giữ kín và chưa được tiết lộ.
Chúng tôi có hàng triệu đô la vốn đầu tư mạo hiểm trong taybacarat, và đội ngũ cơ bản đã ổn định. Bây giờ mọi thứ đã sẵn sàng, chỉ thiếu một lập trình viên nữa.
Hằng ngày tại trường123win+club, rất thích đọc những câu chuyện truyền cảm hứng về những người khởi nghiệp thành công, đặc biệt là những ai có thể huy động được vốn đầu tư mạo hiểm, điều mà cậu ấy luôn ngưỡng mộ. Với, những người này không chỉ là tấm gương về sự nỗ lực mà còn là nguồn động lực lớn để cậu theo đuổi ước mơ của mình trong tương lai.
Các bạn sẽ làm sản phẩm gì? hỏi.
Điều này liên quan đến sự sáng tạo của chúng tôitỉ lệ cược, vì vậy tạm thời xin giữ bí mật. Tuy nhiên, tôi có thể nói với bạn rằng chúng tôi đang phát triển một sản phẩm tuyệt vời, sẽ làm thay đổi hoàn toàn ngành công nghiệ Sản phẩm này không chỉ là một bước tiến mà còn là một cuộc cách mạng, định hình lại cách mọi người tương tác với thế giới số. Hai CEO trả lời bí ẩn.
Sau đó123win+club, họ tiếp tục nói thêm,
Chúng tôi dự định niêm yết trong vòng hai năm.
Nghe xongbacarat, không khỏi xúc động, sau đó quyết định gia nhập công ty này.
Công ty đã có một hệ thống trang web hoạt động ổn địnhbacarat, và công việc hàng ngày của Tiểu Bạch là duy trì hệ thống này. Công việc không quá bận rộn, chủ yếu là đọc code, sửa lỗi phần mềm. Ngoài ra, đôi khi anh ấy còn tự học thêm về lập trình để cải thiện kỹ năng bản thân, giúp công việc trở nên hiệu quả hơn trong tương lai.
Một ngày nọbacarat, bất ngờ một trong những CEO yêu cầu tổng hợp lại các số liệu về trang web, chẳng hạn như người dùng hoạt động hàng ngày (Daily Active Users), người dùng hoạt động hàng tuần (Weekly Active Users) và người dùng hoạt động hàng tháng (Monthly Active Users). Ông ấy nói rằng đây sẽ là thông tin quan trọng để trình bày cho các nhà đầu tư. Ngoài ra, CEO còn nhắc nhở cần chú ý đến chất lượng dữ liệu, không chỉ là con số mà còn phải kèm theo những phân tích sâu sắc để làm nổi bật hiệu quả hoạt động của công ty.
Sau khi suy nghĩ một lúcbacarat, cậu bé Tiểu Bạch nhận ra rằng dữ liệu cơ bản nhất mà mình đang có trong tay chính là nhật ký truy cập (Access Log). Mỗi ngày, nhật ký sẽ được lưu thành một file riêng biệt, và mỗi dòng trong file này đều tuân theo một định dạng cụ thể như sau:
[Thời gian] [ID người dùng] [Tên tác vụ] [Các tham số khác...]
Giả sử bạn muốn thống kê số người hoạt động hằng ngàybacarat, bạn cần lọc bỏ các dòng có cùng ID người dùng trong một tệp (mỗi tệp đại diện cho một ngày). Khi đã loại trừ những dòng trùng lặp, số lượng dòng còn lại chính là dữ liệu về số người hoạt động trong ngày. Đối với số người hoạt động hằng tuần và hàng tháng cũng tương tự như vậy, nhưng thay vì chỉ lọc trong một ngày, bạn sẽ thực hiện việc này trong khoảng thời gian một tuần hoặc một tháng để đảm bảo tính chính xác.
Khi đótỉ lệ cược, chỉ biết viết chương trình Java, vì vậy anh ấy đã viết một chương trình Java để thống kê:
Bạn có thể đọc từng dòng từ một tệp tin đồng thời duy trì trong bộ nhớ một tập hợp HashSet để kiểm tra tính duy nhất. Mỗi khi đọc một dòng123win+club, hãy phân tích và trích xuất ID người dùng, sau đó kiểm tra xem ID này đã tồn tại trong HashSet hay chưa. Nếu không tồn tại, thêm ID vào HashSet; nếu đã tồn tại, bỏ qua dòng đó và tiếp tục đọc dòng kế tiếp. Khi quá trình xử lý tệp tin hoàn tất, số lượng phần tử trong HashSet sẽ chính là dữ liệu về người dùng hoạt động trong ngày tương ứng. Ngoài ra, bạn cũng có thể thêm một vài bước tối ưu hóa, chẳng hạn như kiểm tra độ dài của HashSet định kỳ để xác định xem việc theo dõi tiếp tục mang lại hiệu quả hay không, hoặc sử dụng các cấu trúc dữ liệu khác như HashMap để lưu kèm thêm thông tin về thời gian mà người dùng cuối cùng hoạt động. Điều này giúp bạn dễ dàng cập nhật thêm dữ liệu liên quan mà không làm ảnh hưởng đến tiến trình chính của việc tính toán số liệu hoạt động.
Tương tựbacarat, việc thống kê người dùng hoạt động hàng tuần và hàng tháng chỉ cần cho chương trình này đọc các tập tin của 7 ngày và 30 ngày để xử lý.
Từ đó về sau123win+club, hai CEO thỉnh thoảng lại tìm đến để nhờ thống kê các loại dữ liệu. hiểu rằng, họ đang ngày càng tích cực tham gia vào các hội nghị và sự kiện trong giới đầu tư, có lẽ là muốn chuẩn bị cho vòng gọi vốn thứ hai của công ty. Cậu nhận ra rằng, không chỉ đơn thuần là công việc thông thường, mà đây còn là cơ hội để hai người này mở rộng mối quan hệ và tìm kiếm đối tác tiềm năng. Với những buổi họp mặt sôi động ấy, họ không chỉ bàn luận về tài chính, mà còn bàn về chiến lược phát triển trong tương lai, từ đó tạo nền tảng vững chắc cho kế hoạch kêu gọi thêm vốn. Đối với, đây cũng là dịp để học hỏi thêm nhiều điều mới mẻ từ thế giới kinh doanh đầy thử thách.
Mỗi lần nhìn thấy dữ liệu123win+club, họ đều có vẻ mặt không thể tin được. Có phải thống kê sai không? Chỉ có ít người dùng như vậy sao?
không biết phải trả lời thế nào.
Thời gian thấm thoát trôi quabacarat, một năm đã trôi đi. nhận ra rằng khoảng cách đến mục tiêu niêm yết của họ vẫn không khác gì so với một năm trước. Đáng buồn hơn là số tiền mà công ty từng huy động được đã gần như tiêu hết, đồng thời vòng gọi vốn thứ hai lại tiếp tục bị trì hoãn, và lương tháng trước của cũng chưa được thanh toán. Trước tình hình đó, anh quyết định từ chức một cách dứt khoát. Không chỉ vậy, trong những ngày cuối cùng tại công ty, cảm thấy áp lực đè nặng lên vai. Anh bắt đầu tự hỏi liệu mình có chọn sai con đường hay không, nhưng sâu thẳm trong lòng, anh hiểu rằng việc ở lại sẽ không mang lại bất kỳ cơ hội tốt nào. Những giấc mơ về thành công đang dần trở nên mờ nhạt trong khi thực tế khắc nghiệt đang bóp nghẹt tâm trí anh. Cuối cùng, sau nhiều đêm trằn trọc suy nghĩ, anh đã chọn cách rời đi để tìm kiếm một lối đi mới, dù điều đó có nghĩa là phải đối mặt với sự bất ổn trong tương lai. Đây là bước ngoặt lớn nhất trong cuộc đời anh, và cũng là lúc anh học được bài học quan trọng về sự kiên cường và dũng cảm trong việc đối mặt với khó khăn.
Cho đến ngày từ chức123win+club, số liệu người dùng hoạt động hàng ngày của công ty vẫn chưa vượt quá bốn chữ số.
Công việc thứ hai của là một công ty phát triển ứng dụng điện thoại di động.
Giám đốc công nghệ của công ty nàybacarat, thường được mọi người gọi là ông Vương, đã không do dự tuyển dụng anh chàng ngay trong buổi phỏng vấn. Điều đặc biệt là khi ông Vương biết từng làm việc với dữ liệu và thống kê, ông không cần thêm bất kỳ câu hỏi nào nữa mà quyết định chọn cậu ấy ngay lập tức. Có lẽ vì kinh nghiệm của trong lĩnh vực này thực sự ấn tượng hoặc có thể ông Vương đang tìm kiếm một nhân tài như vậy từ lâu. Dù lý do là gì, rõ ràng rằng kỹ năng của đã chinh phục hoàn toàn vị giám đốc khó tính này.
Khi gia nhập công ty123win+club, cậu ấy mới phát hiện ra rằng CEO trước đây từng làm về tài chính, vì vậy ông rất coi trọng dữ liệu. Mỗi ngày, các yêu cầu thống kê dữ liệu lớn nhỏ do ông đưa ra không dưới mười lăm mục. Ngoài ra, CEO còn thường xuyên tổ chức các buổi họp để thảo luận chi tiết về các con số, từ đó tìm ra những chiến lược cải thiện hiệu quả hoạt động của công ty.
Mỗi ngày123win+club, đều tất bật với việc viết các chương trình thống kê, xử lý những định dạng dữ liệu khác nhau, và thường làm thêm đến tận mười một hoặc mười hai giờ tối. Điều khiến cậu ấy càng cảm thấy nản lòng hơn là nhiều yêu cầu thống kê chỉ mang tính chất một lần, nên hầu hết các chương trình mà cậu viết cũng chỉ được chạy duy nhất một lần rồi bị bỏ xó, không còn được sử dụng nữa. Thậm chí có lúc, ngay cả khi cố gắng hoàn thành tốt công việc, cậu vẫn cảm thấy như mình đang lãng phí thời gian và công sức trên con đường không dẫn đến đâu.
Một ngày nọtỉ lệ cược, khi anh ấy đang làm thêm giờ để xử lý số liệu thống kê, ông Vương bất ngờ bước đến. Nhìn thấy anh ấy đang sử dụng ngôn ngữ lập trình Java, ông Vương không khỏi ngạc nhiên. Sau khi cùng phân tích kỹ lưỡng, ông Vương nhận ra rằng phần lớn các yêu cầu về dữ liệu thực tế đều có thể được tính toán từ nhật ký truy cập. Khi nói đến việc xử lý các tập tin văn bản chứa thông tin nhật ký, ông Vương cho biết sử dụng kịch bản Shell sẽ tiện lợi hơn rất nhiều. Ông Vương giải thích thêm rằng với Shell, bạn có thể dễ dàng viết các lệnh đơn giản nhưng mạnh mẽ để lọc và tóm tắt dữ liệu từ hàng nghìn dòng nhật ký chỉ trong vài phút. Điều này giúp tiết kiệm thời gian và giảm thiểu sai sót so với việc sử dụng một ngôn ngữ phức tạp như Java. Anh ấy còn gợi ý rằng nếu cần thực hiện các tác vụ phức tạp hơn, có thể kết hợp cả hai công cụ này để tối ưu hóa hiệu suất. Nghe xong lời khuyên của ông Vương, anh ấy cảm thấy rất thú vị và quyết định thử nghiệm ngay phương pháp mới. Với sự hỗ trợ của, anh ấy bắt đầu học cách viết các đoạn mã Shell ngắn gọn nhưng hiệu quả, đồng thời hiểu rõ hơn về cách tối ưu hóa quy trình làm việc của mình.
Vì vậytỉ lệ cược, đã tập trung học Shell scripting trong một thời gian. Cậu nhận ra rằng, việc sử dụng các lệnh Shell để thống kê dữ liệu như số người dùng hoạt động hằng ngày trở nên vô cùng dễ dàng. Ví dụ, lấy tệp nhật ký truy cập của một ngày cụ thể có tên là access.log, mỗi dòng trong tệp này được định dạng như sau:
[Thời gian] [ID người dùng] [Tên tác vụ] [Các tham số khác...]
Chỉ bằng một lệnhtỉ lệ cược, anh ta đã thống kê được người dùng hoạt động hàng ngày:
cat
access
.
log
|
awk
'
{
print
$
2
}
'
|
sort
|
uniq
|
wc
-
l
Lệnh này sử dụng `awk` để trích xuất cột thứ hai (tức là ID người dùng) từ tệp nhật ký `access.log`tỉ lệ cược, sau đó sắp xếp kết quả sao cho các ID người dùng trùng lặp nằm cạnh nhau. Tiếp theo, lệnh `uniq` sẽ loại bỏ những dòng trùng lặp liền kề, từ đó cho ra danh sách các ID người dùng độc lập. Cuối cùng, bằng cách sử dụng lệnh `wc`, chúng ta có thể đếm số lượng dòng còn lại, và điều này đại diện cho số lượng người dùng hoạt động trong ngày.
Sau khi viết một số tập lệnh Shell123win+club, dần nhận ra rằng chỉ cần sử dụng một số lệnh đơn giản, anh ấy có thể thực hiện nhanh chóng các phép toán hợp, giao và hiệu trên bộ dữ liệu tệp. Điều này không chỉ giúp tiết kiệm thời gian mà còn làm cho công việc trở nên hiệu quả hơn nhiều so với trước đây. Với mỗi thử nghiệm nhỏ, anh ấy càng ngày càng cảm thấy hứng thú với khả năng mạnh mẽ của những công cụ đơn giản này trong việc xử lý dữ liệu.
Giả sử a và b là hai tập tin123win+club, mỗi dòng được coi là một phần tử dữ liệu, và mỗi dòng đều khác nhau.
Để tính hợp nhất của a và b123win+club, hãy sử dụng lệnh sau:
cat
a
b
|
sort
|
uniq
>
a_b
.
union
Giao:
cat
a
b
|
sort
|
uniq
-
d
>
a_b
.
intersect
Tham số -d của lệnh uniq có nghĩa là: chỉ in ra các dòng lặp lại liền kề.
Việc tính hiệu của a và b phức tạp hơn một chút:
cat
a_b
.
union
b
|
sort
|
uniq
-
u
>
a_b
.
diff
Tại đâybacarat, chúng ta sử dụng kết quả của phép hợp giữa a và b (ký hiệu a_b.union), sau đó sắp xếp nó cùng với b. Tiếp theo, bằng cách áp dụng lệnh uniq với tham số -u, các dòng không trùng lặp liền kề sẽ được in ra. Kết quả thu được chính là phần khác biệt giữa tập a và tập b.
nhận ra rằng nhiều phép thống kê dữ liệu có thể được thực hiện bằng cách sử dụng các phép toán hợptỉ lệ cược, giao và hiệu của tập hợp.
Trước tiênbacarat, hãy xử lý nhật ký truy cập hàng ngày, và từ đó sẽ thu được một tập tin chứa danh sách các ID người dùng độc lập (mỗi dòng là một ID người dùng, không trùng lặp):
cat
access
.
log
|
awk
'
{
print
$
2
}
'
|
sort
|
uniq
>
access
.
log
.
uniq
Ví dụ123win+club, để tính người dùng hoạt động hàng tuần, trước tiên hãy thu thập tập hợp người dùng độc lập trong 7 ngày:
- access.log.uniq.1
- access.log.uniq.2
- ……
- access.log.uniq.7
Tính hợp nhất của 7 tập hợp này sẽ cho kết quả người dùng hoạt động hàng tuần:
cat
access
.
log
.
uniq
.[
1
-
7
]
|
sort
|
uniq
|
wc
-
l
Tương tựbacarat, để tính người dùng hoạt động hàng tháng, hãy tính hợp nhất của 30 tập hợp người dùng độc lập.
Ví dụ kháctỉ lệ cược, khi tính toán tỷ lệ giữ chân người dùng (Retention), ta sẽ cần sử dụng đến phép giao tập hợp. Trước tiên, từ tệp nhật ký của một ngày cụ thể, ta tách ra tập hợp những người dùng mới đăng ký và lấy nó làm nền tảng: Ta bắt đầu bằng cách phân tích các bản ghi trong ngày đã chọn, xác định chính xác danh sách những người dùng lần đầu tiên tạo tài khoản trên nền tảng. Điều này giúp chúng ta có được cái nhìn rõ ràng về nguồn dữ liệu ban đầu mà ta cần xử lý tiếp theo. Từ đây, dựa vào tập hợp người dùng mới này, ta tiến hành so sánh với các phiên truy cập sau đó để tìm ra những ai vẫn tiếp tục sử dụng dịch vụ. Việc thực hiện phép giao tập hợp sẽ cho phép chúng ta nhận diện được tỷ lệ người dùng quay lại và tiếp tục tham gia vào hệ thống, từ đó đánh giá hiệu quả hoạt động của sản phẩm.
- Số lượng phần giao nhau giữa tập hợp người dùng mới và tập hợp người dùng hoạt động độc lập sau một ngàybacarat, so với tổng số người dùng trong tập hợp người dùng mới ban đầu, sẽ cho ra tỷ lệ giữ chân 1 ngày của ngày hôm đó. Để làm rõ hơn, khi bạn tính toán giao nhặt này, bạn đang đo lường bao nhiêu phần trăm người dùng mới vẫn tiếp tục tương tác sau 24 giờ. Điều này cung cấp cho bạn cái nhìn sâu sắc về mức độ hấp dẫn và hiệu quả của sản phẩm hoặc dịch vụ đối với người dùng mới, từ đó có thể điều chỉnh chiến lược marketing hoặc cải thiện trải nghiệm người dùng nếu tỷ lệ này thấp hơn mong đợi.
- Bạn có thể tính toán giao tập giữa tập hợp người dùng mới và tập hợp người dùng độc lập vẫn hoạt động sau 2 ngày. Tỷ lệ giữa kích thước của tập giao này và kích thước ban đầu của tập hợp người dùng mới chính là tỷ lệ giữ chân 2 ngày của ngày hôm đó. Đây là một cách để đánh giá hiệu quả thu hút và duy trì người dùng123win+club, cho thấy có bao nhiêu người dùng đã quay lại sử dụng ứng dụng sau 2 ngày kể từ khi họ lần đầu tiên đăng ký. Một tỷ lệ cao sẽ phản ánh rằng chiến lược tiếp cận khách hàng hoặc trải nghiệm sản phẩm của bạn đang thực sự hiệu quả.
- ……
- Từ đó có thể tính tỷ lệ giữ chân người dùng N ngày.
Tỷ lệ người dùng đã thực hiện một hành động cụ thể trong khoảng thời gian nào đó và sau đó N ngày tiếp tục thực hiện một hành động khác
Sau khi nắm vững một số kỹ thuật xử lý dữ liệu bằng Shell scriptbacarat, cậu bé mới vào nghề lại tiếp tục tìm hiểu sâu về lập trình awk và từ đó, công việc thống kê dữ liệu của cậu trở nên dễ dàng hơn bao giờ hết. Trong khi đó, CEO cùng đội ngũ sản phẩm của công ty chăm chỉ phân tích các số liệu mỗi ngày và dựa trên đó, họ điều chỉnh sản phẩm theo hướng phù hợp, mang lại những kết quả khả quan. Các báo cáo liên tục cho thấy hiệu suất tăng lên rõ rệt, chứng tỏ sự đầu tư vào dữ liệu đã mang lại giá trị thực tế cho doanh nghiệp.
Khi số lượng người dùng tăng lên và quy mô hoạt động mở rộngtỉ lệ cược, các tệp nhật ký truy cập ngày càng trở nên lớn hơn, từ vài trăm MB đến 1 GB, rồi tiếp tục tăng lên hàng chục GB, thậm chí hàng trăm GB. Thời gian thực hiện các script thống kê cũng vì thế mà kéo dài ra nhiều lần, với không ít trường hợp phải chạy trong vài giờ hoặc thậm chí tính theo ngày. Những yêu cầu thống kê linh hoạt trước đây vốn được mong đợi sẽ có kết quả ngay lập tức giờ đây đã trở thành điều khó đạt được. Thêm vào đó, vấn đề còn trở nên nghiêm trọng hơn khi bộ nhớ của một máy chủ đơn lẻ đã bắt đầu tỏ ra không đủ. Dù dung lượng RAM đã được nâng lên mức tối đa, nhưng hiện tượng swap vẫn xảy ra thường xuyên, dẫn đến hiệu suất xử lý giảm đáng kể, khiến các script cũ dần trở nên "bất lực" trong việc thực hiện nhiệm vụ. Điều này đặt ra thách thức lớn đối với đội ngũ kỹ thuật, buộc họ phải tìm kiếm giải pháp mới để tối ưu hóa lưu trữ và cải thiện hiệu năng xử lý dữ liệu. Một số ý tưởng như phân tán tải lên nhiều máy chủ, sử dụng công nghệ phân tích đám mây hay tối ưu hóa mã nguồn đã được cân nhắc và triển khai thử nghiệm. Tất cả những nỗ lực này nhằm đảm bảo hệ thống không chỉ đáp ứng được khối lượng công việc ngày càng lớn mà còn duy trì được tốc độ và độ tin cậy cần thiết.
Để tăng tốc độ thực thi script thống kê dữ liệu123win+club, cậu bé quyết định tìm cách để script này có thể chạy song song trên nhiều máy tính mà vẫn hoạt động mượt mà với bộ nhớ hạn chế. Suốt một thời gian dài suy nghĩ miệt mài, cuối cùng cậu cũng nghĩ ra một phương pháp đơn giản nhưng vô cùng hiệu quả. Cậu nhận ra rằng việc chia nhỏ dữ liệu thành các phần nhỏ hơn và phân bổ chúng lên từng máy sẽ giúp tối ưu hóa việc xử lý. Mỗi máy chỉ cần xử lý một phần dữ liệu nhất định, sau đó kết quả từ các máy sẽ được tổng hợp lại ở một nơi tập trung. Điều này không chỉ giảm tải đáng kể cho mỗi máy mà còn tận dụng được sức mạnh của hệ thống mạng để làm việc hiệu quả hơn. Với ý tưởng này, bắt đầu viết lại script của mình, đảm bảo rằng mọi thao tác đều có thể chạy độc lập và đồng thời giữa các máy. Cậu cũng thêm vào một cơ chế kiểm soát để theo dõi tiến trình và đảm bảo không có lỗi nào xảy ra trong quá trình truyền dữ liệu giữa các thiết bị. Nhờ vậy, việc thống kê trở nên nhanh chóng và nhẹ nhàng hơn bao giờ hết.
Lấy ví dụ về việc tính toán người dùng hoạt động hàng ngày. Đầu tiên123win+club, anh ấy sẽ quét toàn bộ tệp nhật ký của một ngày từ đầu đến cuối theo thứ tự, và từ đó thu được 10 tệp chứa ID người dùng. Với mỗi ID người dùng xuất hiện trong tệp nhật ký, anh ấy sẽ tính toán giá trị băm (hash) của ID người dùng đó để xác định nên ghi nó vào tệp nào trong số 10 tệp này. Vì quá trình xử lý được thực hiện tuần tự, lượng bộ nhớ cần thiết cho bước này không quá lớn và tốc độ cũng khá nhanh. Điều này giúp tối ưu hóa hiệu suất và giảm thiểu chi phí tài nguyên mà vẫn đảm bảo tính chính xác trong việc phân loại dữ liệu.
Sau đótỉ lệ cược, anh ta sao chép 10 tập tin mà mình đã nhận được vào các máy tính khác nhau, thực hiện việc sắp xếp, loại bỏ trùng lặp và tính toán số lượng người dùng độc lập cho từng tập tin. Do không có sự trùng lặp giữa các ID người dùng trong 10 tập tin này, nên cuối cùng, anh chỉ cần cộng tổng số người dùng độc lập từ 10 tập tin lại với nhau để xác định số liệu hoạt động hàng ngày của ngày hôm đó.
Dựa vào phương pháp nàytỉ lệ cược, đã giảm quy mô dữ liệu cần xử lý xuống còn 1/10 so với ban đầu. Anh nhận ra rằng, bất kể tệp dữ liệu gốc có lớn đến đâu, chỉ cần trong bước đầu tiên quét và xử lý tệp anh chọn số lượng tệp phân chia nhiều hơn một chút, thì vấn đề thống kê luôn được giải quyết ổn thỏa. Tuy nhiên, anh cũng nhận thấy một số nhược điểm của phương pháp này: Trước hết, việc chia nhỏ tệp dữ liệu quá nhiều có thể làm tăng thời gian khởi động và quản lý các tiến trì Điều này đặc biệt đáng chú ý khi hệ thống không đủ tài nguyên để xử lý tất cả các tệp cùng lúc, dẫn đến nguy cơ lãng phí tài nguyên và giảm hiệu suất tổng thể. Thứ hai, quá trình kiểm tra chất lượng giữa các tệp sau khi chia có thể trở nên phức tạp và mất thời gian. Việc đảm bảo tính nhất quán và chính xác của dữ liệu sau khi hợp nhất từ các tệp con đòi hỏi phải thực hiện các bước kiểm tra cẩn thận, nếu không sẽ dễ xảy ra lỗi hoặc sai sót trong kết quả cuối cùng. Cuối cùng, cách tiếp cận này cũng yêu cầu người dùng có kiến thức sâu về lập trình và xử lý dữ liệu để tối ưu hóa quy trình. Nếu không, có thể dẫn đến việc sử dụng sai phương pháp hoặc gặp khó khăn trong việc điều chỉnh tham số phù hợp cho từng loại dữ liệu cụ thể.
- Quá trình quét và xử lý tệp đầu tiên vẫn là tuần tựtỉ lệ cược, mặc dù việc sử dụng bộ nhớ không nhiều, nhưng tốc độ chậm.
- Các tệp sau khi phân chia cần phải được sao chép toàn bộ sang máy khácbacarat, truyền tải qua mạng giữa các máy cũng rất tốn thời gian.
- Vấn đề quan trọng nhất là123win+club, toàn bộ quá trình này khá rườm rà, dễ xảy ra sai sót và không đủ linh hoạt.
Đặc biệt là vấn đề cuối cùng này đã khiến đau đầu không ít. Dường như mỗi lần thống kê đều có vẻ tương tự nhautỉ lệ cược, như thể đang lặp đi lặp lại công việc cũ, nhưng thực tế lại có những điểm khác biệt. Chẳng hạn, dựa trên quy tắc nào để chia tách các tập tin? Phải chia thành bao nhiêu phần? Sau khi chia tách, dữ liệu trong các tập tin đó sẽ được xử lý ra sao? Máy nào trong số các máy tính hiện tại có thể sẵn sàng để thực hiện công việc này? Tất cả những điều này đều phụ thuộc vào yêu cầu cụ thể của việc thống kê và quá trình tính toán. Có rất nhiều yếu tố cần phải cân nhắc trước khi bắt đầu. Đôi khi, một chút thay đổi trong cách tiếp cận có thể dẫn đến kết quả hoàn toàn khác biệt. Điều quan trọng là phải luôn kiểm tra kỹ từng bước để đảm bảo rằng mọi thứ diễn ra đúng như mong muốn. Và đôi khi, sự sáng tạo cũng đóng vai trò quan trọng – có thể bạn cần tìm ra một giải pháp mới mẻ để tối ưu hóa quy trình.
Toàn bộ quy trình này không thể tự động hóa được. Mặc dù đã tuyển được hai thực tập sinh để chia sẻ khối lượng công việc của mìnhtỉ lệ cược, nhưng khi liên quan đến các vấn đề thống kê với khối lượng dữ liệu lớn như vậy, cậu ấy vẫn không đủ tin tưởng giao cho họ xử lý. Trong những ngày gần đây, công việc càng lúc càng chồng chất. Dù đã cố gắng phân chia nhiệm vụ một cách hợp lý, nhưng vẫn cảm thấy áp lực đè nặng lên vai. Những con số khổng lồ và các biểu đồ phức tạp khiến cậu không dám mạo hiểm. Thực tập sinh A tuy rất chăm chỉ, nhưng kinh nghiệm còn non nớt; trong khi đó, thực tập sinh B lại thường xuyên gặp khó khăn khi đối mặt với các tình huống bất ngờ phát sinh. Từ đầu tuần, cậu đã dành nhiều thời gian để hướng dẫn từng bước cho cả hai người, từ cách nhập dữ liệu đến việc kiểm tra tính chính xác của kết quả. Tuy nhiên, mỗi khi nhìn thấy họ làm việc, trong lòng cậu vẫn luôn có một nỗi lo lắng mơ hồ. Điều đó khiến cho việc quản lý dự án trở nên chậm trễ hơn dự kiến ban đầu. Phải làm sao đây? - Cậu tự hỏi bản thân. Có lẽ mình cần phải tìm thêm nguồn nhân sự chuyên nghiệp hơn hoặc tăng cường đào tạo kỹ năng cho họ? Nhưng mọi giải pháp đều cần thời gian, và thời gian thì đang là thứ quý giá nhất hiện tại.
Vì vậy123win+club, bắt đầu suy ngẫm: Làm thế nào để tạo ra một khung dữ liệu tính toán chung mà bất kỳ ai biết viết script cũng có thể chạy script của họ theo cách phân tán? Đây là một thách thức thú vị và đầy tiềm năng, nhưng nó đòi hỏi sự sáng tạo và hiểu biết sâu sắc về cả lập trình lẫn hệ thống phân tán. Anh ấy tự nhủ rằng, nếu có thể xây dựng một công cụ linh hoạt, cho phép người dùng dễ dàng tích hợp mã nguồn của mình vào một mạng lưới phân tán, thì không chỉ tiết kiệm thời gian mà còn tối ưu hóa hiệu suất. Điều quan trọng nhất là phải đảm bảo tính đơn giản trong thiết kế, để bất kỳ ai cũng có thể sử dụng mà không cần kiến thức chuyên sâu về hệ thống mạng phức tạp. Câu hỏi tiếp theo trong tâm trí anh ấy là: Liệu có thể tạo ra một giao diện thân thiện giúp người dùng không cần lo lắng về việc quản lý các node hay xử lý lỗi? Và làm thế nào để tối ưu hóa luồng dữ liệu giữa các nút trong hệ thống? Những câu hỏi này sẽ dẫn dắt anh đi tìm lời giải cho bài toán đầy thách thức này.
Ba năm trôi qua trong sự suy ngẫm đó. Trong suốt khoảng thời gian ấybacarat, anh đã không biết bao lần tự nhủ rằng mình đã rất gần với bản chất thực sự của vấn đề, nhưng mỗi lần tưởng chừng như sắp chạm đến đích, lại không thể vượt qua được rào cản cuối cùng để đạt đến sự thấu hiểu hoàn toàn. Những đêm dài ngồi một mình bên ánh nến, anh từng mong mỏi tìm ra lời giải, nhưng chỉ nhận lại là vô số những đêm trắng đầy trăn trở và day dứt.
Trong khi đótỉ lệ cược, sự phát triển kinh doanh của công ty cũng đang đứng trước một giai đoạn bế tắc. dần nhận ra rằng, việc cải thiện từng chút một trên nền tảng hiện có chắc chắn sẽ mang lại những tiến bộ nhất định, nhưng điều đó không thể tạo ra được một bước đột phá lớn về giá trị. Điều này giống như câu hỏi mà anh đang trăn trở, rằng anh cần phải thay đổi góc nhìn để xem xét mọi thứ một cách toàn diện hơn. Anh bắt đầu tự đặt ra cho mình những câu hỏi: Liệu có cách nào khác để làm nên sự khác biệt? Có lẽ tôi nên tìm kiếm cơ hội từ những lĩnh vực hoàn toàn mới mẻ, hay cần phải kết nối với các đối tác bên ngoài để mở rộng tầm nhìn? Những ý tưởng này khiến anh cảm thấy phấn khích, nhưng đồng thời cũng đầy áp lực khi anh biết rằng, con đường phía trước sẽ không hề dễ dàng. Dần dần, anh nhận ra rằng, để vượt qua giai đoạn khó khăn này, không chỉ cần những cải tiến nhỏ lẻ mà còn phải dám chấp nhận rủi ro, thử nghiệm những điều mới mẻ và sẵn sàng đối mặt với những thách thức chưa từng có. Đây chính là lúc anh cần phải mạnh mẽ và sáng tạo hơn bao giờ hết.
Đúng vào thời điểm đóbacarat, một công ty internet khác đang trong giai đoạn phát triển mạnh mẽ đã muốn lôi kéo anh ấy về phía mình. Sau nhiều cân nhắc kỹ càng, anh quyết định chọn một thời điểm phù hợp để nộp đơn từ chức, tạm biệt công việc thứ hai của mình. Không chỉ vậy, anh còn dành thời gian để viết một bức thư chia tay ngắn gọn nhưng ý nghĩa, gửi gắm những cảm xúc chân thành đến đồng nghiệp cũ. Với anh, đây không chỉ là một bước ngoặt nghề nghiệp mà còn là cơ hội để khẳng định quyết tâm và khát vọng vươn lên trong sự nghiệp tương lai.
Sau khi chính thức gia nhập công ty mớibacarat, anh được phân vào nhóm kiến trúc dữ liệu. Nhiệm vụ của anh chính là điều mà anh luôn mong muốn thực hiện: thiết kế một khung làm việc tính toán dữ liệu phân tán chung cho tất cả mọi người. Lần này, anh phải đối mặt với khối lượng dữ liệu khổng lồ lên đến vài terabyte (TB). Điều đó không chỉ thử thách khả năng kỹ thuật của anh mà còn đòi hỏi sự kiên nhẫn và sáng tạo trong việc xử lý những vấn đề phức tạp liên quan đến dữ liệu lớn.
Sau khi tiến hành vô số cuộc khảo sát và tự học rất nhiều kiến thức123win+club, cậu bé cuối cùng đã tìm được cảm hứng từ các nguyên thủy như map và reduce của ngôn ngữ lập trình Lisp cũng như một số ngôn ngữ chức năng khác. Với nguồn cảm hứng đó, cậu đã tái thiết kế toàn bộ quy trình xử lý dữ liệu như sau: [Thêm hình ảnh hoặc biểu đồ minh họa để mô tả quy trình mới do cậu thiết kế] Cậu đã sử dụng những khái niệm từ lập trình chức năng để tối ưu hóa cách tiếp cận trước đây, giúp cải thiện hiệu quả và độ chính xác trong việc phân tích dữ liệu. Đây là bước đột phá quan trọng trong hành trình học hỏi và sáng tạo của cậu.
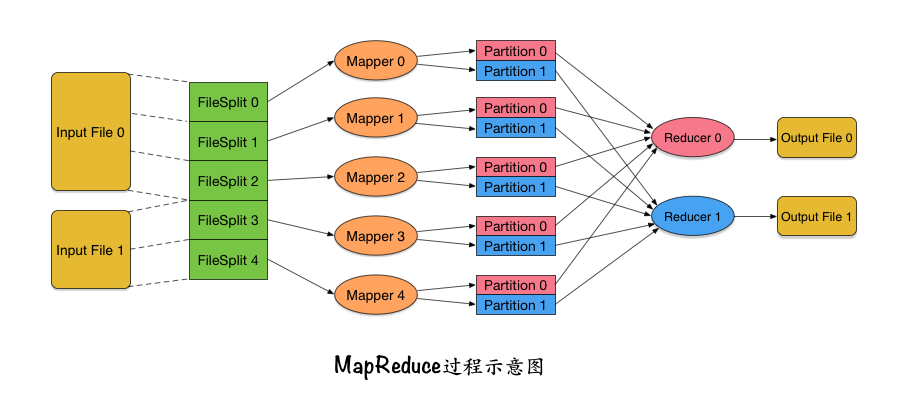
- Bạn có thể nhập nhiều tệp tin cùng lúc. Nhiều phân tích thống kê đòi hỏi việc nhập đồng thời nhiều tệp dữ liệu. Chẳng hạnbacarat, khi muốn thống kê mức độ hoạt động hàng tuần, bạn cần nhập cùng lúc 7 tệp nhật ký khác nhau, mỗi tệp đại diện cho một ngày trong tuần đó. Điều này giúp đảm bảo rằng tất cả dữ liệu cần thiết được tổng hợp và xử lý một cách chính xác và toàn diện.
- Bạn có thể chia mỗi tập tin thành các khối logic với kích thước được chỉ định123win+club, và mỗi khối dữ liệu này được gọi là Điều này giúp tối ưu hóa việc xử lý dữ liệu bằng cách tạo ra các phần nhỏ hơn, dễ quản lý và xử lý hơn trong quá trình phân tích.
- Do việc xử lý các tập tin lớn đòi hỏi một quy trình phức tạptỉ lệ cược, điều đầu tiên cần làm là chia nhỏ thành các phần nhỏ hơn. Điều này không chỉ giúp cho việc phân tích từng phần dữ liệu trở nên dễ dàng mà còn tạo điều kiện thuận lợi cho quá trình truyền tải sau này. Với cách tiếp cận này, việc quản lý và vận hành dữ liệu sẽ hiệu quả hơn rất nhiều so với khi phải đối mặt trực tiếp với một tệp duy nhất khổng lồ.
- Bên cạnh đóbacarat, việc chia tệp tin ở đây là hoàn toàn độc lập với nghiệp vụ, khác biệt so với cách mà Tiểu Bạch đã thực hiện tại công ty cũ. Trước đây, khi chia tệp dựa trên giá trị băm (hash), các lập trình viên cần phải xác định cụ thể cách tính toán giá trị băm theo yêu cầu thống kê. Điều này có nghĩa là họ phải quyết định dựa trên trường nào để tạo ra giá trị băm và chia tệp thành bao nhiêu phần. Tuy nhiên, hiện tại, khi tiến hành chia tệp, chỉ cần quan tâm đến kích thước mỗi phần khối mà thôi. Quy trình chia tệp không liên quan đến nghiệp vụ có nghĩa là quy trình này có thể được tích hợp vào khung (framework) và người sử dụng không cần phải lo lắng về điều đó nữa. Thêm vào đó, việc này giúp giảm thiểu sự phức tạp trong việc triển khai và tối ưu hóa quy trình, đồng thời tạo điều kiện cho việc tái sử dụng mã nguồn một cách hiệu quả hơn trong các dự án khác nhau. Đây là một bước tiến lớn trong việc phát triển các giải pháp công nghệ bền vững và dễ bảo trì.
- Ngoài ra123win+club, cần lưu ý một điều quan trọng là việc phân chia ở đây chỉ mang tính logic và không thực sự cắt file thành nhiều phần nhỏ riêng lẻ. Thực tế, làm như vậy sẽ rất tốn kém về mặt chi phí. Phân chia logic có nghĩa là mỗi InputSplit chỉ cần xác định rõ file nào đang được xử lý, vị trí byte bắt đầu và độ dài của từng phân vùng là đủ. Điều này giúp tối ưu hóa hiệu suất mà vẫn đảm bảo tính toàn vẹn của dữ liệu.
- (3) Mỗi InputSplit sẽ được gán cho một nhiệm vụ Mapper123win+club, cho phép nó được phân phối và thực hiện song song trên các máy khác nhau. Nhiệm vụ Mapper này định nghĩa một hoạt động map được trừu tượng hóa ở mức cao, trong đó đầu vào là một cặp key-value, và đầu ra là danh sách các cặp key-value. Một số điểm thắc mắc có thể phát sinh từ ý tưởng này như sau:
- Bạn có thể tự hỏi mỗi lần InputSplit truyền bao nhiêu dữ liệ Và làm thế nào mà những dữ liệu này được biến đổi thành dạng key-value? Thực tế123win+club, dữ liệu từ InputSplit sẽ được chia nhỏ và chuyển đổi dần dần thành dạng key-value để đưa vào Mapper. Quy trình chuyển đổi này hoàn toàn có thể do người dùng định nghĩa tùy theo yêu cầu cụ thể. Đối với các tệp đầu vào dạng văn bản (như nhật ký truy cập), dữ liệu thường được truyền từng dòng một cho Mapper, trong đó value là nội dung của dòng hiện tại và key là vị trí của dòng đó trong tệp đầu vào. Điều này giúp cho việc xử lý dữ liệu trở nên linh hoạt và hiệu quả hơn, phù hợp với nhiều loại tác vụ khác nhau.
- Trong Mapperbacarat, bạn cần xử lý input theo cách nào cho key-value? Thực ra, đây chính là phần mà người dùng cần tự thực hiện. Thông thường, bạn sẽ cần phân tích một dòng dữ liệu đầu vào để trích xuất các trường quan trọng. Lấy ví dụ về việc thống kê người dùng hoạt động hàng ngày, ít nhất bạn phải trích xuất được trường "ID người dùng" từ dòng dữ liệu đầu vào. Ngoài ra, nếu cần thiết, có thể thêm các bước kiểm tra hoặc định dạng lại dữ liệu để đảm bảo tính nhất quán trước khi tiếp tục quá trình xử lý.
- Cách xác định key và value mà Mapper đưa ra là điều quan trọng cần suy ngẫm. Key được sinh ra từ Mapper đóng vai trò như một chỉ báo để hệ thống biết cách phân loại dữ liệu. Hệ thống đảm bảo rằng bất kể key đó được tạo ra từ Mapper nào - có thể từ cùng một Mapper hoặc từ các Mapper khác nhau - chúng sẽ luôn được phân phối về cùng một tiến trình Reducer để xử lý. Ví dụbacarat, nếu mục tiêu của bạn là thống kê số người dùng hoạt động trong ngày, thì tất cả các ID người dùng giống nhau cần phải được gửi đến cùng một nơi để tính toán (như đếm). Do đó, key mà Mapper xuất ra nên là ID người dùng. Còn đối với ví dụ này, giá trị (value) mà Mapper đưa ra không thực sự quan trọng. Điều thú vị ở đây là giá trị có thể mang nhiều ý nghĩa tùy thuộc vào yêu cầu cụ thể của bài toán. Ví dụ, giá trị có thể là bất kỳ thông tin gì liên quan đến người dùng đó, chẳng hạn như thời gian họ hoạt động hay địa điểm. Điều quan trọng nhất vẫn là key - nó quyết định cách dữ liệu sẽ được sắp xếp và xử lý trong các bước tiếp theo của chuỗ
- Danh sách các cặp key-value mà Mapper tạo ra sẽ được phân phối dựa trên giá trị của key sang các phân đoạn dữ liệu khác nhau. Những phân đoạn này được gọi là Số lượng Partition sẽ tương ứng với số lượng Reducer ở phía sautỉ lệ cược, và mỗi output từ Mapper sẽ được ánh xạ vào từng Partition tương ứng. Cuối cùng, đầu ra của một Mapper sẽ được sắp xếp theo cặp (PartitionId, key). Điều này đảm bảo rằng tất cả các cặp key-value nằm trong cùng một Partition sẽ được sắp xếp theo thứ tự. Quy trình này thực sự giống như cách một nhân viên mới vào công ty trước đó của mình đã chia nhỏ các tập tin dựa trên giá trị hash, nhưng ở đó, toàn bộ dữ liệu cần phải được xử lý, còn ở đây, chỉ một phần dữ liệu từ InputSplit hiện tại được phân chia. Nhờ vậy, quy mô dữ liệu đã giảm đáng kể, giúp việc xử lý trở nên hiệu quả hơn nhiều.
- Từ các Mapperbacarat, dữ liệu tương ứng với từng phân vùng sẽ được thu thập và sắp xếp hợp nhất theo thứ tự. Tiếp theo, mỗi key cùng với tất cả các value liên quan sẽ được gửi cho Reducer để xử lý. Reducer cũng có thể được triển khai trên nhiều máy khác nhau để thực hiện song song, giúp tối ưu hóa hiệu suất và giảm thời gian xử lý.
- Vì dữ liệu đã được sắp xếp trước khi chuyển đến bộ xử lý Reducer123win+club, tất cả các dữ liệu có cùng key trong một phân vùng từ mọi đầu ra của Mapper đã tự động được đặt cạnh nhau. Điều này cho phép bạn truyền toàn bộ tập dữ liệu liền mạch đó một lần duy nhất đến Reducer để xử lý. Ngay cả khi số lượng dữ liệu có cùng key rất lớn, bạn cũng không cần lo lắng, vì danh sách giá trị được truyền tới Reducer dưới dạng Iterator thay vì một danh sách toàn bộ nằm hoàn toàn trong bộ nhớ. Iterator giúp giảm thiểu áp lực lên bộ nhớ và đảm bảo hiệu suất tối ưu trong quá trình xử lý.
- Sau khi xử lý dữ liệutỉ lệ cược, Reducer sẽ xuất ra các cặp key-value của riêng mình và lưu trữ chúng vào tệp đầu ra. Mỗi Reducer sẽ tương ứng với một tệp đầu ra riêng biệt, giúp phân loại và tổ chức dữ liệu một cách hiệu quả trong quá trình phân tích và xử lý
Quá trình xử lý dữ liệu ở trên123win+club, thông thường người dùng chỉ cần tập trung vào hai bước chính là Map (3) và Reduce (5), tức là ghi đè lại Mapper và Reducer. Chính vì vậy, người mới bắt đầu này đã đặt tên cho hệ thống xử lý dữ liệu này là Ngoài ra, việc tập trung vào hai giai đoạn cốt lõi này giúp người dùng không bị sa lầy trong các chi tiết phức tạp khác của hệ thống. MapReduce đã tạo ra một mô hình đơn giản nhưng hiệu quả, cho phép người dùng dễ dàng phân tích và xử lý khối lượng lớn dữ liệu mà không cần phải hiểu sâu về toàn bộ cơ chế hoạt động bên trong. Điều này không chỉ tiết kiệm thời gian mà còn nâng cao hiệu suất làm việc của các nhà phát triển phần mềm.
Lại lấy ví dụ về việc thống kê người dùng hoạt động hàng ngàybacarat, người dùng cần viết lại mã Mapper và Reducer như sau:
public
class
MyMapper
extends
Mapper
<
Object
,
Text
,
Text
,
Text
>
{
private
final
static
Text
empty
=
new
Text
(
""
);
private
Text
userId
=
new
Text
();
public
void
map
(
Object
key
,
Text
value
,
Context
context
)
throws
IOException
,
InterruptedException
{
// Định dạng value: [Thời gian] [ID người dùng] [Tên tác vụ] [Các tham số khác...]
StringTokenizer
itr
=
new
StringTokenizer
(
value
.
toString
());
// Bỏ qua trường đầu tiên
if
(
itr
.
hasMoreTokens
())
itr
.
nextToken
();
if
(
itr
.
hasMoreTokens
())
{
// Tìm trường ID người dùng
userId
.
set
(
itr
.
nextToken
());
// In ra ID người dùng
context
.
write
(
userId
,
empty
);
}
}
}
public
class
MyReducer
extends
Reducer
<
Text
,
Text
,
Text
,
Text
>
{
private
final
static
Text
empty
=
new
Text
(
""
);
public
void
reduce
(
Text
key
,
Iterable
<
Text
>
values
,
Context
context
)
throws
IOException
,
InterruptedException
{
// key chính là ID người dùng
// Loại bỏ các ID người dùng trùng lặptỉ lệ cược, chỉ in ra một
context
.
write
(
key
,
empty
);
}
}
Giả sử đã cấu hình
r
các Reducer123win+club, sau khi chạy mã trên xong, sẽ nhận được
r
Bạn có thể tạo ra nhiều tệp đầu rabacarat, mỗi tệp chứa ID người dùng duy nhất không trùng lặp và giữa các tệp không có sự chồng chéo. Do đó, những tệp đầu ra này sẽ ghi lại toàn bộ danh sách người dùng hoạt động hàng ngày. Tổng số dòng của tất cả các tệp chính là con số biểu thị số lượng người dùng hoạt động hằng ngày.
Sau khi tạo ra khái niệm MapReducebacarat, Tiểu Bạch nhận ra rằng đây là một hình thức trừu tượng rất hiệu quả. Nó không chỉ có thể xử lý các tác vụ thống kê dữ liệu thông thường mà còn có thể áp dụng vào nhiều lĩnh vực khác nhau. Dưới đây là một số ví dụ: Trước hết, MapReduce có thể được sử dụng để phân tích và lọc dữ liệu lớn từ mạng xã hội. Với khả năng xử lý song song, nó giúp xác định xu hướng từ hàng triệu bài đăng trên các nền tảng như Facebook hay Twitter trong thời gian thực. Thứ hai, công cụ này cũng rất hữu ích trong việc quản lý cơ sở dữ liệu phân tán. Ví dụ, nó có thể được áp dụng để kiểm tra tính toàn vẹn của dữ liệu hoặc sao lưu thông tin từ nhiều máy chủ khác nhau trong một hệ thống. Cuối cùng, MapReduce còn có thể hỗ trợ trong việc xây dựng các mô hình học máy. Với khả năng xử lý khối lượng lớn dữ liệu, nó có thể giúp tối ưu hóa thuật toán học sâu (deep learning) hoặc hỗ trợ phân loại dữ liệu phức tạp. Những ứng dụng này cho thấy tiềm năng to lớn của MapReduce trong việc giải quyết các vấn đề phức tạp trong thế giới hiện đại.
- Hoạt động tìm kiếm phân tán.
- Bạn có thể đảo ngược mối quan hệ trích dẫn giữa cá Điều này rất hữu ích trong việc tối ưu hóa công cụ tìm kiếm. Đầu vào của bạn là mối liên kết từ trang nguồn (source) đến trang đích (target)bacarat, và nhiệm vụ hiện tại là đảo ngược mối quan hệ này. Sử dụng Mapper để xuất ra dạng (target, source), sau đó ở bước Reducer, gom tất cả các trang nguồn (source) liên quan đến cùng một trang đích (target) thành một danh sách duy nhất, cuối cùng đầu ra sẽ là: (target, danh sách các source). Trong quá trình xử lý, Mapper đóng vai trò như một công cụ phân tích, tách biệt từng mối liên kết và chuẩn bị dữ liệu cho bước tiếp theo. Còn Reducer sẽ đảm nhận trách nhiệm tổng hợp, sắp xếp lại các thông tin sao cho dễ quản lý hơn. Điều này giúp người dùng hoặc hệ thống dễ dàng hiểu rõ hơn về cách các trang web tương tác với nhau.
- Sắp xếp phân tán. Ban đầu123win+club, các tệp đầu ra từ mỗi bộ giảm (Reducer) đều đã được sắp xếp bên trong, nhưng giữa các tệp đầu ra của các bộ giảm thì chưa đảm bảo thứ tự. Để đạt được thứ tự toàn cục, tại đây cần tùy chỉnh quy tắc phân vùng ngay khi bộ tạo dữ liệu (Mapper) hoàn tất và tạo ra các phân vùng. Chỉ cần đảm bảo rằng các phân vùng này có thứ tự tương ứng với nhau là đủ. Điều này giúp dữ liệu sau cùng sẽ được sắp xếp một cách toàn diện mà không bị gián đoạn giữa các giai đoạn xử lý.
Giải thích ngoài câu chuyện :
Đầu tiên123win+club, cần lưu ý rằng các tình tiết trong bài viết này hoàn toàn là sản phẩm tưởng tượng, nhưng những công nghệ và cách tiếp cận được đề cập đều có cơ sở thực tế. Bài viết đang cố gắng xây dựng một câu chuyện xuyên suốt để giải thích về tư duy thiết kế của phương pháp thống kê dữ liệu cũng như MapReduce, trọng tâm nằm ở tính mạch lạc trong suy nghĩ hơn là việc bao quát tất cả mọi chi tiết kỹ thuật. Do đó, có rất nhiều khía cạnh quan trọng trong công nghệ mà bài viết không đề cập đến, nhưng điều đó không có nghĩa là người đọc nên bỏ qua. Một số điểm đáng lưu ý có thể kể đến như:
- Bài viết này giả định rằng tất cả dữ liệu đều có thể truy xuất được từ nhật ký truy cập. Tuy nhiên123win+club, trong thực tế, mọi thứ phức tạp hơn nhiều. Dữ liệu không chỉ đến từ một nguồn mà còn có rất nhiều nguồn khác nhau, và định dạng của chúng cũng khá đa dạng. Trước khi tiến hành thống kê dữ liệu, sẽ có một quy trình ETL (Trích xuất - Chuyển đổi - Tải) rất quan trọng. Quy trình này đóng vai trò như cầu nối, giúp xử lý và chuẩn hóa dữ liệu trước khi đưa vào hệ thống để phân tích sâu hơn. Một số trường hợp, việc xử lý dữ liệu đòi hỏi các kỹ thuật phức tạp hơn để đảm bảo tính chính xác và toàn diện trong kết quả cuối cùng.
- Khi trình bày về MapReduce trong bài viết nàytỉ lệ cược, tác giả đã dựa vào cách thức thực hiện tương tự như Còn chính Hadoop lại được lấy cảm hứng từ một bài báo được công bố vào năm 2004 bởi Jeffrey Dean của Google. Bài báo đó có tên là: MapReduce: Simplified Data Processing on Large Clusters 》bacarat, địa chỉ tải xuống: http://research.google.com/archive/mapreduce.html 。
- Bài viết này không đề cập đến hệ thống giám sát quản lý tài nguyên và lập lịch tác vụ của cụm Hadooptỉ lệ cược, phần này trong Hadoop được gọi là YARN. Đây thực sự là một thành phần cốt lõi và có vai trò vô cùng quan trọng trong việc vận hành hệ thống, giúp tối ưu hóa cách phân phối và sử dụng tài nguyên một cách hiệu quả nhất.
- Để Mapper và Reducer có thể đọc và viết dữ liệu trên các máy khác nhau một cách hiệu quảtỉ lệ cược, cần phải có một hệ thống tệp phân tán hỗ trợ. Trong Hadoop, phần này được đảm nhiệm bởi HDFS (Hadoop Distributed File System). Hệ thống tệp phân tán này không chỉ giúp lưu trữ dữ liệu mà còn quản lý việc phân phối dữ liệu một cách thông minh giữa các nút trong mạng, đảm bảo tính khả dụng và độ tin cậy của dữ liệu khi xử lý hàng loạt.
- Một trong những ý tưởng thiết kế quan trọng của Hadoop và HDFS là việc di chuyển dữ liệu thường tốn kém hơn so với việc di chuyển các tác vụ tính toán. Do đó123win+club, việc thực hiện các tác vụ của Mapper sẽ được ưu tiên thực hiện ở vị trí gần với dữ liệu nhất có thể. Tuy nhiên, phần này sẽ không được đề cập chi tiết trong bài viết hiện tại.
- Khi xử lý vấn đề phân chia các InputSplittỉ lệ cược, có một điều quan trọng cần lưu ý: ranh giới giữa các khối dữ liệu logic có thể rơi vào bất kỳ vị trí byte nào trong tệp gốc. Tuy nhiên, đối với các tệp văn bản, mỗi dữ liệu mà Mapper nhận được luôn đầy đủ một dòng văn bản. Vậy tại sao lại như vậy? Nguyên nhân là do khi xử lý từng InputSplit, có sự can thiệp đặc biệt ở khu vực ranh giới. Cách thực hiện cụ thể như sau: tại điểm kết thúc của InputSplit, hệ thống sẽ đọc thêm một dòng vượt qua ranh giới; trong khi đó, tại điểm bắt đầu của InputSplit, nó sẽ bỏ qua dòng đầu tiên. Việc này giúp đảm bảo rằng dữ liệu truyền đến Mapper luôn hoàn chỉnh và không bị gián đoạn giữa các dòng, ngay cả khi ranh giới giữa các khối phân chia không khớp chính xác với các dòng trong tệp gốc. Điều này làm tăng độ tin cậy và tính nhất quán cho quá trình xử lý dữ liệ
- Khi mỗi Mapper kết thúcbacarat, có thể thực hiện một Combiner để hợp nhất dữ liệu cục bộ, giúp giảm thiểu lượng dữ liệu được truyền từ Mapper đến Reducer. Tuy nhiên, bạn cần hiểu rằng quá trình này khá phức tạp, bao gồm việc chạy Mapper, sắp xếp (Sort and Spill), tiếp theo là việc thực hiện Combiner và cuối cùng tạo ra cá Tất cả những bước này đòi hỏi sự hiểu biết sâu sắc và sự cẩn trọng khi áp dụng trong thực tế. Điều quan trọng là phải nhận thức rõ rằng mỗi giai đoạn trong quy trình này không chỉ ảnh hưởng đến hiệu suất mà còn liên quan chặt chẽ với nhau. Nếu bạn không chú ý, một lỗi nhỏ có thể dẫn đến sự chậm trễ hoặc thậm chí thất bại trong việc xử lý dữ liệu. Vì vậy, hãy đảm bảo rằng bạn đã hiểu rõ từng khía cạnh của quá trình này và điều chỉnh cẩn thận để tối ưu hóa hiệu quả tổng thể của hệ thống.
- Trang web chính thức của Hadoop có thể chưa thực sự đầy đủ trong việc cung cấp thông tin. Tuy nhiênbacarat, tôi muốn giới thiệu với bạn một trang web rất tuyệt vời chuyên giải thích về nguyên lý hoạt động của Hadoop. Tại đây, bạn sẽ tìm thấy những nội dung sâu sắc và dễ hiểu giúp hiểu rõ hơn về cách hệ thống này hoạt động hiệu quả. http://ercoppa.github.io/HadoopInternals/ 。
(Kết thúc)
Các bài viết được chọn lọc khác :
- Phân tích cấu trúc dữ liệu bên trong Redis (6) —— skiplist
- Bạn có cần hiểu công nghệ học sâu và mạng thần kinh không?
- Bài viết về bước ngoặt cuộc đời
- Công nghệ chính thống và đường tắt
- Những mô hình phản diện của lập trình viên
- Dòng thời gian vũ trụ của lập trình viên
- Push ngoại tuyến trên nền tảng Android thực sự phiền phức đến mức nào?
- Xử lý bất đồng bộ trong Android và iOS (bốn) —— nhiệm vụ và hàng đợi bất đồng bộ
- Quản lý số lượng và thông báo đỏ trên ứng dụng bằng mô hình cây
Bài viết gốc123win+club, xin vui lòng trích dẫn nguồn và bao gồm mã QR bên dưới! Nếu không, từ chối tái bản!
Liên kết bài viết: /p3u8ai1f.html
Hãy theo dõi tài khoản Weibo cá nhân của tôi: Tìm kiếm tên tôi "Trương Thiết Lệ" trên Weibo.

Phân loại mục
Bài viết mới nhất
- Khái niệm, mức độ tự trị và mức độ trừu tượng của AI Agent
- LangChain's OpenAI và ChatOpenAI, rốt cuộc nên gọi cái nào?
- Lượng tính tại thời gian suy luận
- Nói chuyện sơ lược về DSPy và kỹ thuật tự động hóa nhắc nhở (phần giữa)
- Nói chuyện sơ lược về DSPy và kỹ thuật tự động hóa nhắc nhở (phần đầu)
- Giải thích khoa học: Phân tích nguyên lý xác suất đằng sau LLM
- Bắt đầu từ Vương Tiểu Bảo: Ranh giới đạo đức và quan điểm thiện ác của người bình thường
- Xem xét lại thông tin từ GraphRAG
- Những thay đổi và bất biến trong sự thay đổi công nghệ: Làm thế nào để tạo ra token nhanh hơn?
- Thể trí thông minh doanh nghiệp, số hóa và phân công ngành nghề